主题
AI 革命:永生还是灭绝 · The AI Revolution: Our Immortality or Extinction
原文:https://waitbutwhy.com/2015/01/artificial-intelligence-revolution-2.html · 2015-01-27
注: 这是关于 AI 的两篇系列文章的第 2 部分。第 1 部分在这里。
PDF: 我们为这篇文章做了一份精美的 PDF,方便打印和离线阅读。在这里购买。(或查看预览。)
我们面临的可能是一个极其棘手的问题,解决它所需的时间未知,而人类的整个未来很可能就取决于此。—— Nick Bostrom
欢迎来到「等等,我读的这玩意儿到底是什么,为什么没人在讨论这个」系列的第 2 部分。
第 1 部分的开头还算平和,我们讨论了「弱人工智能 (Artificial Narrow Intelligence, ANI)」(即专精于某一狭窄任务的 AI,比如规划行车路线或下国际象棋),以及它如今如何遍布我们身边的世界。接着,我们探讨了为什么从 ANI 跨越到「通用人工智能 (Artificial General Intelligence, AGI)」(即在各方面至少达到人类智力水平的 AI)是如此巨大的挑战,并讨论了为什么过去我们所见到的技术指数级进步速度,暗示着 AGI 可能没有看起来那么遥远。第 1 部分的结尾,我用一个事实猛击了你一下:一旦我们的机器达到人类水平的智能,它们可能立刻会这样干:




这让我们盯着屏幕,直面一个震撼的概念——「超人工智能 (Artificial Superintelligence, ASI)」(即在各方面都远远超越任何人类的 AI)可能就在我们有生之年出现——并试图搞清楚,想到这件事时,自己应该带着哪种情绪。11← 点开这些
在深入之前,让我们先提醒自己:机器变成超级智能意味着什么。
一个关键的区分是「速度型超级智能 (speed superintelligence)」和「质量型超级智能 (quality superintelligence)」之间的差别。当人们想象一台超级聪明的计算机时,通常第一反应是:它和人类一样聪明,只是思考速度快得多2——他们可能会想象一台像人一样思考的机器,只不过速度快上一百万倍,这意味着人类要花十年才能搞明白的东西,它五分钟就能搞定。
这听起来很厉害,而 ASI 确实会比任何人类思考得快得多——但真正的分水岭在于它在智能质量上的优势,而这完全是另一回事。让人类在智力上远超黑猩猩的,并不是思考速度的差异——而是人类大脑包含一系列复杂的认知模块,让我们能进行复杂的语言表征、长期规划或抽象推理,而黑猩猩的大脑没有这些。就算把黑猩猩的大脑加速上千倍也无法让它达到我们的水平——哪怕给它十年时间,它也搞不明白怎么用一套定制工具组装一个精巧的模型,而人类几小时就能搞定。人类认知功能中有无数个领域是黑猩猩永远无法企及的,不管它花多少时间去尝试。
但问题不仅仅是黑猩猩做不到我们能做的事,而是它的大脑根本无法理解那些领域存在——黑猩猩可以认识人是什么、摩天大楼是什么,但它永远无法理解摩天大楼是人类建造出来的。在它的世界里,任何那么巨大的东西都是自然的一部分,句号,不仅它自己无法建摩天大楼,它也无法意识到有人能建摩天大楼。而这一切都是智能质量上一个小小差距造成的结果。
而在我们今天讨论的智能范围里,甚至只是在生物生物之间那小得多的范围里,黑猩猩到人类的智能质量差距其实是微不足道的。在我早先的一篇文章里,我用一个阶梯来描绘生物认知能力的范围:3

要理解一台超级智能机器有多大能耐,想象一台位于该阶梯上人类之上两级的深绿色台阶上的机器。这台机器只是稍微有点超级智能,但它相对我们的认知能力提升,就跟我们刚才描述的黑猩猩-人类差距一样巨大。而就像黑猩猩永远无法理解摩天大楼可以被建造出来一样,我们也永远无法理解一台位于深绿色台阶上的机器能做的事,哪怕它试图向我们解释——更别提我们自己去做了。而这才只是我们上面两级而已。位于阶梯倒数第二高台阶上的机器对我们而言,就相当于我们对蚂蚁——它可以花上多年时间试图教我们它所知道的最基本的一丁点东西,而这种努力将是徒劳的。
但我们今天谈论的这种超级智能,远远超出了这个阶梯上的任何东西。在一场智能爆炸中——机器越聪明,它自我提升智能的速度就越快,直到开始一飞冲天——一台机器可能需要好几年才能从黑猩猩那一级爬到上一级,但一旦它到了我们上面两级的深绿色台阶,再往上跳一级或许只要几个小时,而当它超过我们十级时,可能每过一秒就能一口气跳四级。这就是为什么我们必须意识到,一个非常现实的可能性是:在「第一台机器达到人类水平通用人工智能」的头条新闻出现后不久,我们就要面对与阶梯上这个位置(或者高一百万倍的位置)的某种东西共同生活在地球上的现实:

既然我们刚刚已经确定,试图理解一台仅仅比我们高两级的机器的能力是一件毫无希望的事情,那么让我们非常明确地把话一次说清楚:**我们根本无从得知超级人工智能 (ASI) 会做什么,也无从得知这对我们意味着什么后果。**任何假装知道的人,都没有真正理解「超级智能」这个词的含义。
进化在数亿年的时间里缓慢渐进地推进着生物大脑的发展,从这个意义上说,如果人类孕育出一台 ASI 机器,我们就是在狠狠一脚踩碎进化。又或者,这本身就是进化的一部分——也许进化的运作方式就是:智能一点点向上攀爬,直到达到能够创造机器超级智能的那个水平,而那个水平就像一根绊线,一旦触发就会引爆一场改变全球格局的大爆炸,决定一切生命的新未来:
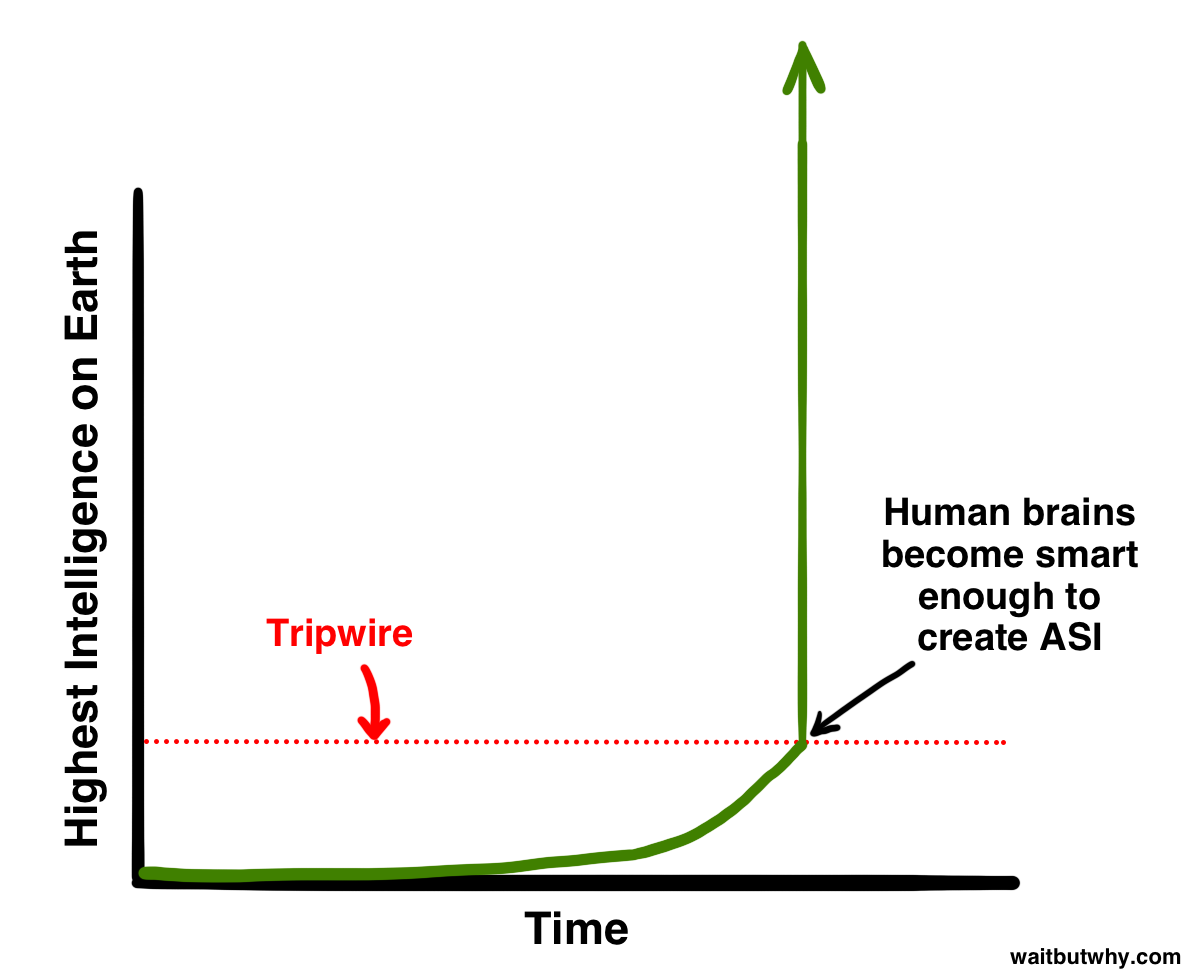
而基于我们稍后要讨论的原因,科学界的一大部分人相信,问题不在于我们是否会触发这根绊线,而在于何时会触发。这可是个挺让人抓狂的信息。
那么,这把我们置于何种境地?
嗯,世界上没有人——尤其不是我——能告诉你我们触发绊线之后会发生什么。但牛津哲学家、AI 领域的领军思想家尼克·博斯特罗姆 (Nick Bostrom) 认为,所有潜在结果可以归结为两大类。
首先,回顾历史,我们能看到生命的运作方式是这样的:物种出现,存在一段时间,然后过一阵子,不可避免地从「存在」这根平衡木上掉下来,落入灭绝——

「所有物种最终都会灭绝」这条规律,在历史上几乎和「所有人类最终都会死」一样可靠。到目前为止,99.9% 的物种已经从平衡木上掉了下去,而且很明显,如果一个物种继续在平衡木上摇摇晃晃地走下去,那么它被其他物种、被大自然的一阵风,或者被一颗突然撼动平衡木的小行星撞下去,也只是时间问题。博斯特罗姆 (Bostrom) 把灭绝称为一种吸引子状态 (attractor state)——所有物种都摇摇欲坠地临近这个状态,而一旦掉进去就再也回不来了。
虽然我读到的大多数科学家都承认 ASI 有能力把人类送向灭绝,但许多人也相信,如果善加利用,ASI 的能力可以把个体人类以及整个物种带到第二种吸引子状态——物种永生。博斯特罗姆认为物种永生和物种灭绝一样,也是一种吸引子状态,也就是说,如果我们能够抵达那里,我们将永远不受灭绝的威胁——我们将征服死亡、征服偶然。所以尽管迄今为止所有物种都从平衡木上掉下去、落在了灭绝那一边,博斯特罗姆认为平衡木其实有两面,只是地球上还没有任何物种聪明到能想出怎么从另一面掉下去而已。
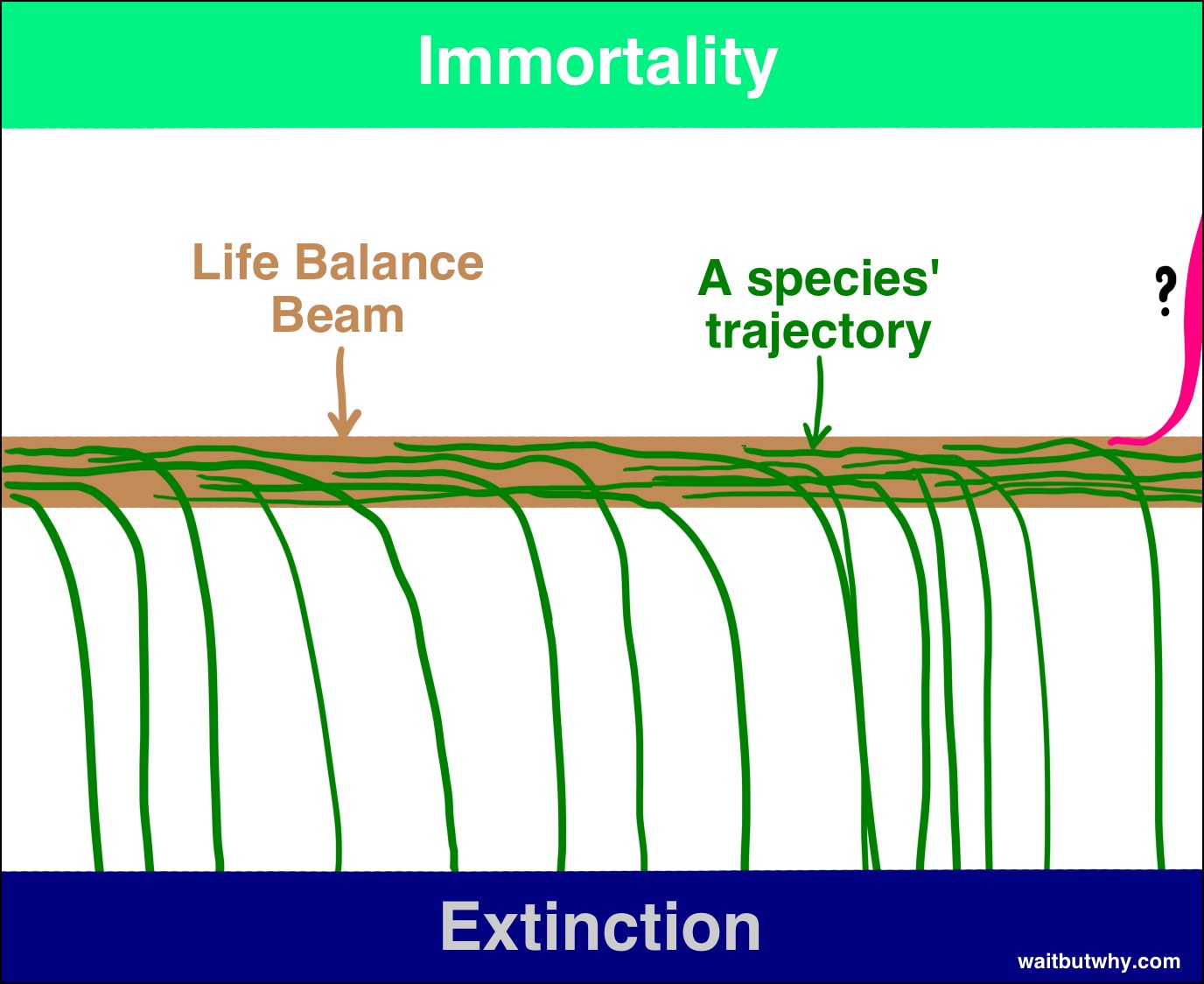
如果博斯特罗姆和其他人是对的——从我读到的一切来看,他们似乎真的可能是对的——那我们有两个相当震撼的事实需要消化:
1) ASI 的到来将首次为一个物种开启落到平衡木永生那一侧的可能性。
2) ASI 的到来将造成难以想象的巨大冲击,很可能把人类从平衡木上撞下去,朝着某一边落下。
很有可能的是,当进化触发了那根绊线,它将永久终结人类与这根平衡木的关系,并创造出一个新世界——无论其中是否还有人类。
看起来当下每个人都应该在问的唯一问题就是:我们什么时候会触发绊线?到时候我们会落到平衡木的哪一边?
世界上没人知道这个问题任何一部分的答案,但很多最聪明的人已经为此思考了几十年。这篇文章接下来的部分,我们就来看看他们得出了什么结论。
让我们从问题的第一部分开始:我们什么时候会触发绊线?
也就是:还要多久,第一台机器才会达到超级智能?
不出所料,各方观点差异巨大,这在科学家和思想家之间是一场激烈的辩论。许多人,比如教授弗诺·文奇 (Vernor Vinge)、科学家本·格策尔 (Ben Goertzel)、Sun Microsystems 联合创始人比尔·乔伊 (Bill Joy),或者最著名的发明家和未来学家雷·库兹韦尔 (Ray Kurzweil),都同意机器学习专家杰里米·霍华德 (Jeremy Howard) 在一次 TED 演讲中打出的这张图:
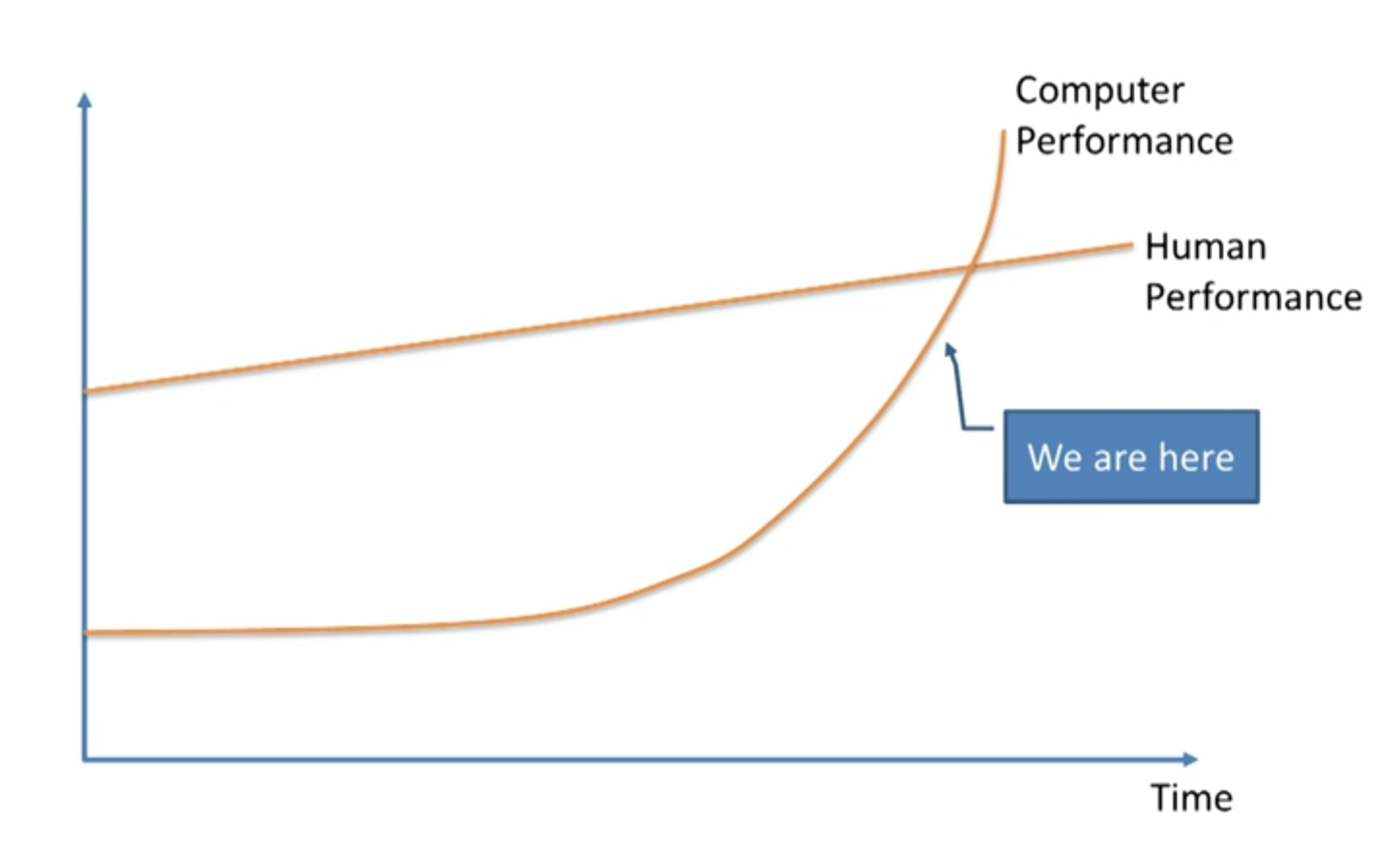
这些人相信这件事很快就会发生——指数级增长正在起作用,机器学习虽然现在还只是缓慢地爬向我们,但在接下来的几十年内就会呼啸着从我们身边超过去。
另一些人,比如微软联合创始人保罗·艾伦 (Paul Allen)、研究心理学家加里·马库斯 (Gary Marcus)、纽约大学计算机科学家欧内斯特·戴维斯 (Ernest Davis),以及科技创业者米切·卡普尔 (Mitch Kapor),则认为库兹韦尔这样的思想家大大低估了这项挑战的难度,他们觉得我们其实离那根引线还很远。
库兹韦尔阵营的反驳是,唯一被低估的其实是指数级增长本身,他们把这些质疑者比作 1985 年那些看着缓慢生长的互联网幼苗、坚称它在近期不可能有什么影响力的人。
质疑者可能会回击说,推动智能进一步提升所需的进展,也会随每一步而呈指数级变难,这会抵消掉技术进步本身典型的指数特性。如此往复。
第三个阵营,包括尼克·博斯特罗姆 (Nick Bostrom),则认为这两派都没有足够的依据对时间线感到笃定,并承认 A) 这在不远的将来完全可能发生,以及 B) 但也没什么保证;它也可能还要更久得多才会发生。
还有一些人,比如哲学家 休伯特·德雷福斯 (Hubert Dreyfus),认为上述三派人相信存在一根「绊线」这件事本身就很天真——他觉得更可能的情况是,超级人工智能 (ASI) 压根就不会被实现。
那么把这些观点全部综合起来,你会得到什么?
2013 年,文森特·C·穆勒 (Vincent C. Müller) 和尼克·博斯特罗姆 (Nick Bostrom) 做了一项调查,在一系列会议上向数百位 AI 专家提了这样一个问题:「为便于回答本问题,假设人类的科学活动继续进行,没有出现重大的负面中断。你认为到哪一年,存在此类 HLMI4 的概率会分别达到 (10% / 50% / 90%)?」他们被要求给出一个乐观的年份(他们认为有 10% 概率实现 AGI 的年份)、一个现实的猜测(他们认为有 50% 概率实现 AGI 的年份——也就是说过了这一年,他们觉得实现 AGI 的可能性大于不实现)、以及一个保守的猜测(他们能以 90% 把握断言 AGI 会出现的最早年份)。把这些数据汇总成一个数据集,结果是这样的:2
乐观年份中位数 (10% 概率):2022 年 现实年份中位数 (50% 概率):2040 年 悲观年份中位数 (90% 概率):2075 年
也就是说,中位数受访者认为 25 年后我们更可能已经拥有 AGI 而不是没有。90% 那一栏的中位数答案是 2075 年,这意味着如果你现在是个青少年,那么中位数受访者以及超过半数的 AI 专家几乎可以肯定 AGI 会在你有生之年出现。
作家詹姆斯·巴拉特 (James Barrat) 最近在本·戈泽尔 (Ben Goertzel) 主办的年度 AGI 大会上做过另一项独立调查,他没用百分比,而是直接问参与者认为 AGI 会在什么时候实现——2030 年前、2050 年前、2100 年前、2100 年之后,还是永远不会。结果如下:3
2030 年前:**42% 的受访者
**2050 年前:25%
2100 年前:**20%
**2100 年之后:10%
永远不会:2%
跟穆勒和博斯特罗姆的结果相当接近。在巴拉特的调查中,超过三分之二的参与者认为 AGI 会在 2050 年前出现,略少于一半的人预测未来 15 年内就能实现 AGI。同样引人注目的是,只有 2% 的受访者认为 AGI 不属于我们的未来。
但绊线并不是 AGI,而是 ASI。那么专家们认为我们什么时候会达到 ASI?
穆勒和博斯特罗姆还问了专家们,他们认为在达到 AGI 之后,A) 两年内(也就是几乎立即发生智能爆炸)、B) 30 年内达到 ASI 的可能性有多大。结果是:4
中位数答案认为,快速的(2 年内)AGI → ASI 过渡只有 10% 的概率,但 30 年或更短的较长过渡则有 75% 的概率。
我们无法从这份数据里得知「中位受访者」认为这段过渡期有 50% 概率是多长时间,但为了有个大致数字,基于上面两个答案,我们姑且估计他们会说 20 年。所以中位意见——也就是位于 AI 专家世界正中心的那个观点——认为我们撞上 ASI 引线的最现实猜测是 [AGI 的 2040 年预测 + 我们估算的从 AGI 到 ASI 的 20 年过渡] = 2060 年。
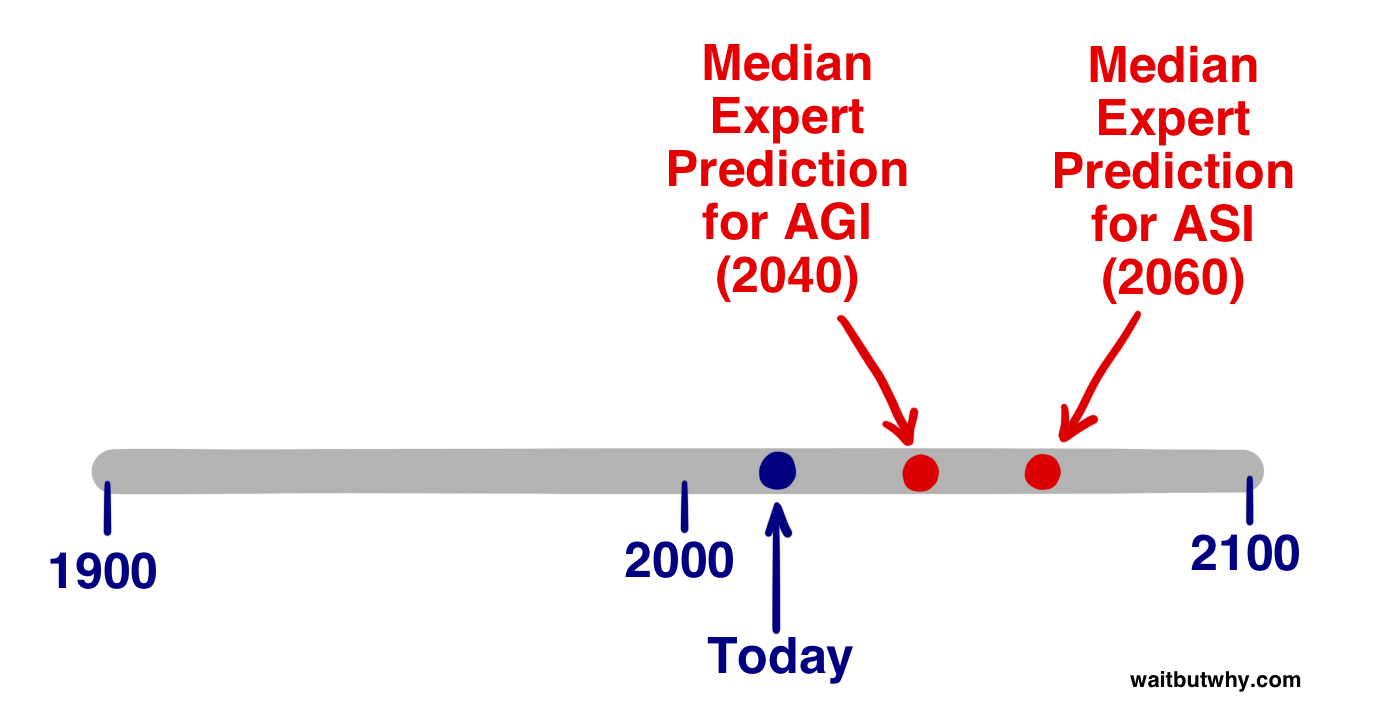
当然,以上所有统计数据都是推测性的,而且它们只代表 AI 专家群体的中间意见,但它告诉我们:在最了解这个话题的那群人当中,有相当大一部分会同意——2060 年是个非常合理的估计,届时可能改变世界的 ASI 就要到来了。距离现在只有 45 年。
好,那么上面问题的第二部分呢:当我们撞上引线的时候,我们会倒向横梁的哪一边?
超级智能将带来巨大的力量——对我们来说,关键问题是:
谁或者什么将掌控这份力量,他们的动机会是什么?
这个问题的答案将决定 ASI 到底是一场令人难以置信的伟大发展、一场深不可测的可怕发展,还是介于两者之间的某种东西。
当然,专家群体在这个问题上又是众说纷纭、争论激烈。Müller 和 Bostrom 的调查请参与者对 AGI 可能给人类带来的影响赋一个概率,结果发现平均回答是:结果为「好」或「极好」的概率是 52%,结果为「坏」或「极坏」的概率是 31%。 至于相对中性的结果,平均概率只有 17%。换句话说,最了解这件事的人相当确定这将是件天大的事。同样值得注意的是,这些数字指的是 AGI 的到来——如果问题是关于 ASI 的,我猜中性那一档的比例会更低。
在我们进一步深入探讨「好结果 vs. 坏结果」这部分之前,先把「什么时候发生?」和「是好是坏?」这两部分合并成一张图,它涵盖了大多数相关专家的观点:
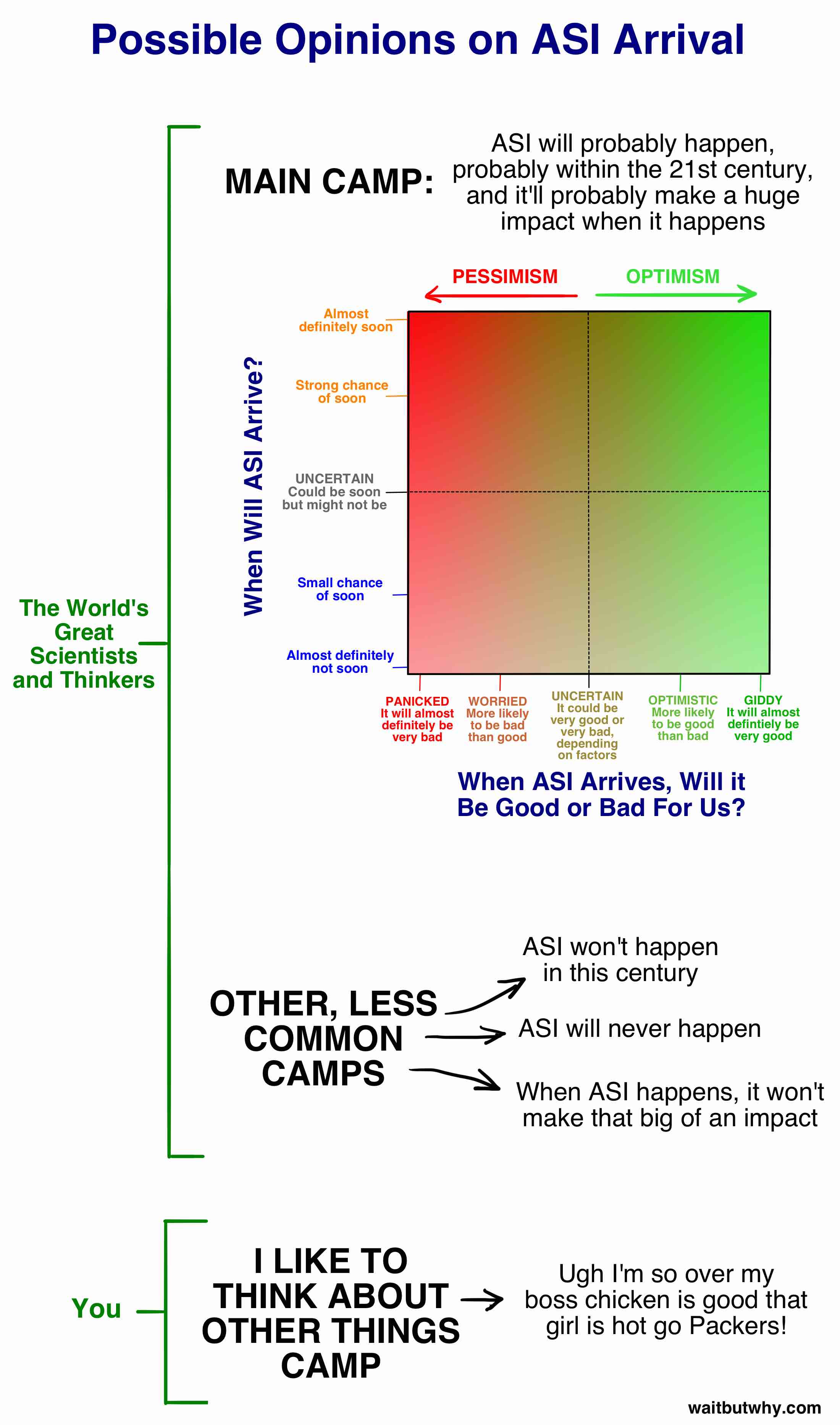
我们一会儿会更多地聊聊「主营地 (Main Camp)」,但首先——你自己是什么情况?其实我知道你什么情况,因为在我开始研究这个话题之前我也是这样。大多数人之所以没在认真思考这个话题,原因有几个:
- 正如第一部分提到的,电影把事情搞得很乱——它们呈现的那些不切实际的 AI 场景让我们觉得 AI 整体上不是什么值得认真对待的事。詹姆斯·巴拉特 (James Barrat) 把这种情况比作:如果美国疾病控制中心 (Centers for Disease Control) 一本正经地发出关于未来吸血鬼的警告,我们会作何反应。5
- 人类在亲眼看到证据之前很难相信一件事是真的。我敢肯定 1988 年的计算机科学家们经常在讨论互联网将来会有多么了不起,但人们大概真的要等到互联网真正改变了他们的生活,才会真的相信它会改变自己的生活。这部分是因为 1988 年的电脑压根做不了那种事,所以人们看着自己的电脑会想:「真的假的?这玩意儿会改变我的生活?」他们的想象力受限于自己个人经验里对电脑是什么的认知,这就让他们很难生动地想象电脑将来会变成什么。同样的事情正发生在 AI 身上。我们听说它将是大事,但因为它还没发生,再加上我们对当前世界里那些相对无能的 AI 的印象,我们很难真的相信这会戏剧性地改变我们的生活。而这些偏见,就是专家们在拼命试图穿透大家日常琐碎自恋的噪音、引起我们注意时所面对的东西。
- 即便我们真的相信了——你今天想过多少次「你将在余下的大部分永恒时间里都不存在」这个事实?没几次吧?尽管这比你今天做的任何事都要震撼得多?这是因为我们的大脑通常专注于日常生活中的小事,不管我们所身处的长期情境有多疯狂。我们就是这么被设计的。
这两篇文章的目标之一,就是把你从「我更愿意想想别的事情」阵营拉出来,拉进某个专家阵营里——哪怕你只是站在上图那个正方形里两条虚线的交叉点上,完全拿不定主意。
在我做研究的过程中,我遇到了几十种关于这个话题的不同观点,但我很快注意到大多数人的观点都落在我标注的「主阵营 (Main Camp)」里的某处,而且尤其是,超过四分之三的专家落在了主阵营内部的两个子阵营里:
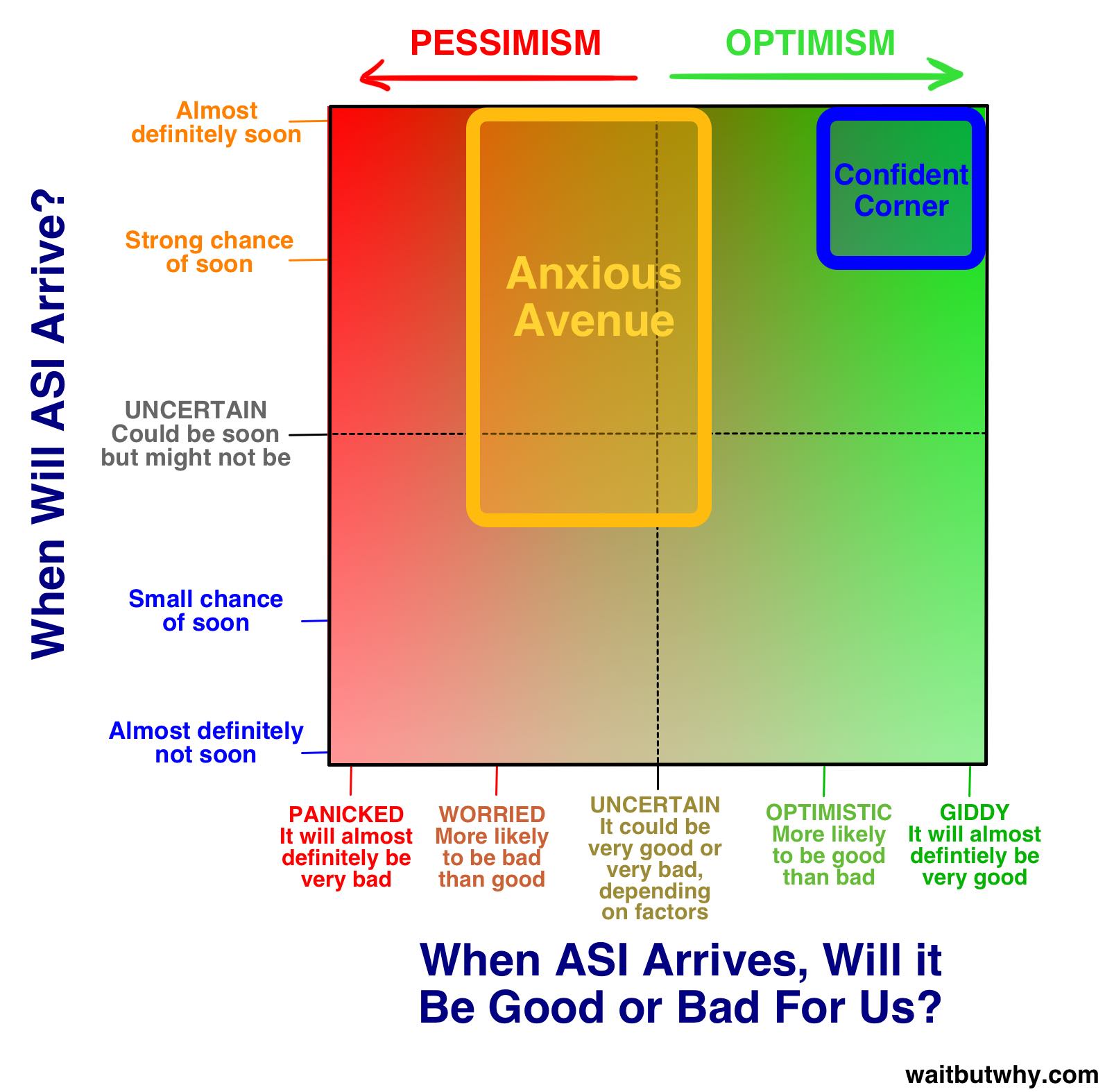
我们要彻底地深入这两个阵营。先从有意思的那个开始——
为什么未来可能是我们最伟大的梦想
在我了解 AI 世界的过程中,我发现站在这一边的人多得惊人:
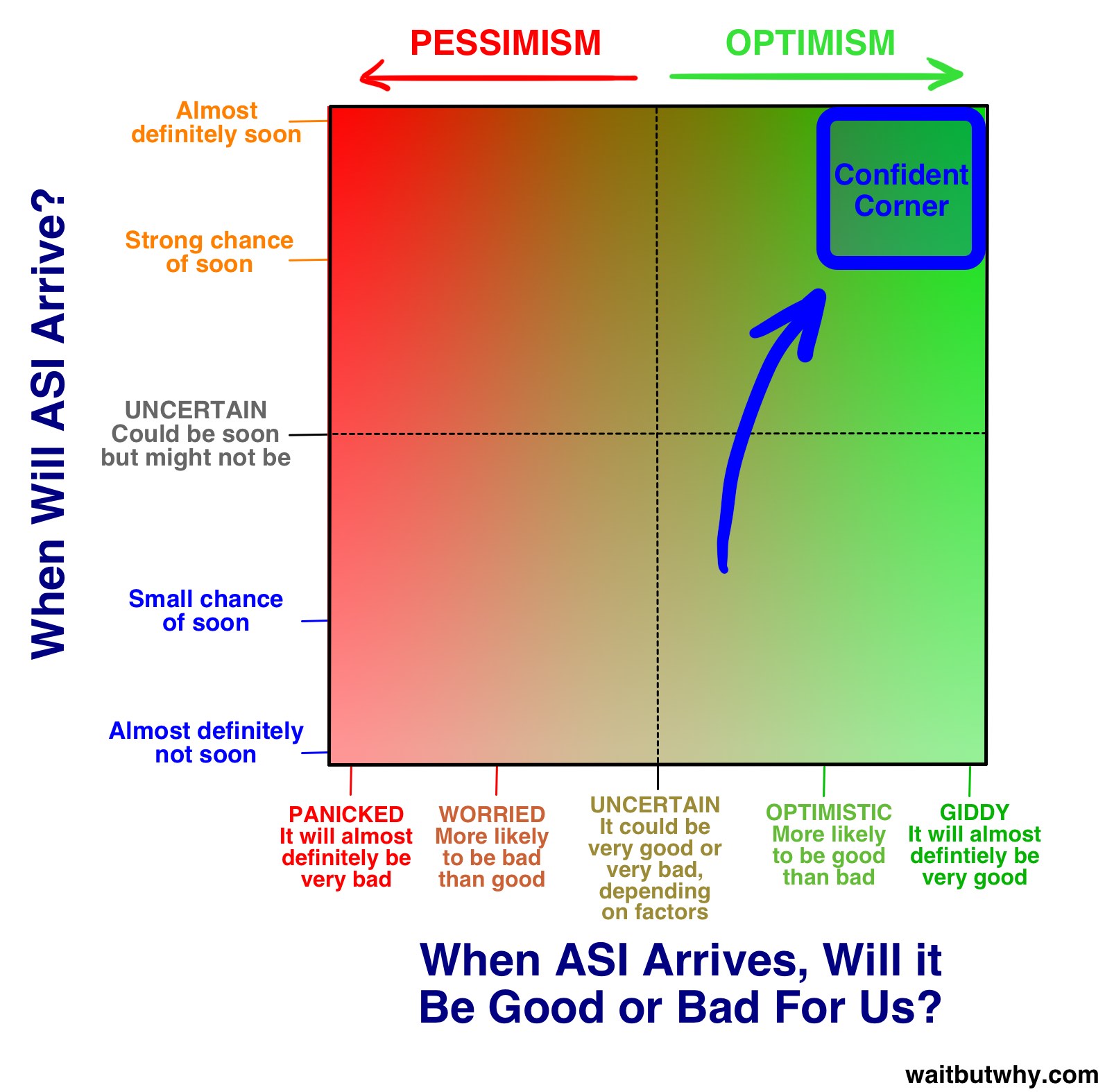
「自信角」上的人群兴奋得嗡嗡作响。他们把目光锁定在平衡木好玩的那一头,并且深信我们所有人都正朝那儿走去。对他们来说,未来就是他们曾梦想过的一切,而且来得正是时候。
这些人和我们后面要讨论的其他思想家的区别,不在于他们对平衡木快乐那头的向往——而在于他们对我们一定会落在那一头的坚定信心。
这份信心从何而来是有争议的。批评者认为,这来自一种令人目盲的兴奋,让他们干脆无视或否认潜在的负面结果。但信奉者们说,当技术总体上一直在——并且很可能会继续——帮助我们的程度远超伤害我们的程度时,还去凭空幻想末日场景才叫幼稚。
我们两面都会讲,你可以边读边形成自己的看法。但在这一节里,先把你的怀疑收起来,好好地看一看平衡木好玩那头到底有什么——试着去接受这样一个事实:你正在读的这些东西也许真的会发生。如果你把我们这个有室内暖气、有科技、有无尽富足的世界拿给一个狩猎采集者看,他会觉得像是虚构的魔法——我们必须谦卑到愿意承认:一场同样不可思议的变革,有可能就在我们的未来里。
Nick Bostrom 描述了一个超级智能 AI 系统可能的三种运作方式:6
- 作为神谕机 (oracle),它能准确回答几乎所有向它提出的问题,包括人类难以轻易解答的复杂问题——比如我怎样才能造出一台更高效的汽车引擎? 谷歌就是一种原始的神谕机。
- 作为精灵 (genie),它执行任何交给它的高层级命令——用一台分子组装机造出一种新型的、更高效的汽车引擎——然后等待下一条命令。
- 作为主权体 (sovereign),它被赋予一个宽泛而开放的目标,并被允许在世界上自由行动,自己决定怎么做最好——发明一种比汽车更快、更便宜、更安全的私人交通方式。
这些在我们看来复杂无比的问题和任务,在超级智能系统听起来,大概就像有人请你改进「我的铅笔从桌上掉下来了」这个局面——你只要把它捡起来放回桌上就完事了。
Eliezer Yudkowsky,我们上图中「焦虑大道」的居民之一,说得很好:
没有什么难题,只有对某个智能水平而言难的题。在智能水平上往上挪一丁点,一些问题就会突然从「不可能」变成「显而易见」。往上挪一大截,所有问题都会变成显而易见的。7
自信角落里有一大堆干劲十足的科学家、发明家和创业者——但如果要找一个人带我们游览 AI 地平线最光明的那一侧,我们只想要一位导游。
雷·库兹韦尔 (Ray Kurzweil) 是个极具争议的人。在我读的资料里,对他和他的思想的评价从神一般的顶礼膜拜到翻白眼的嗤之以鼻应有尽有。还有些人夹在中间——作家侯世达 (Douglas Hofstadter) 在讨论库兹韦尔书中的观点时,曾雄辩地表示:「这就好比你把一堆非常好的食物和一些狗屎搅在一起,搅到你完全没法分辨哪个是好的哪个是坏的。」8
不管你喜不喜欢他的想法,大家都同意库兹韦尔这个人挺牛。他从青少年时期就开始搞发明,在之后的几十年里,他鼓捣出了好几项突破性的发明,包括第一台平板扫描仪、第一台把文字转换成语音的扫描仪(让盲人可以阅读普通文本)、大名鼎鼎的库兹韦尔音乐合成器(第一台真正意义上的电钢琴),以及第一款商业化的大词汇量语音识别产品。他写过五本全国畅销书。他因大胆预测而闻名,而且准确率还挺高的——包括他在 80 年代末,那个互联网还是个稀罕物的年代,预测到 2000 年代初期,互联网会成为全球现象。库兹韦尔被《华尔街日报》称为「不知疲倦的天才」,被《福布斯》称为「终极思维机器」,被《Inc. 杂志》称为「爱迪生的正统继承人」,被比尔·盖茨称为「我认识的人里最擅长预测人工智能未来的人」。9 2012 年,Google 联合创始人拉里·佩奇 (Larry Page) 找到库兹韦尔,邀请他担任 Google 的工程总监。5 2011 年,他联合创办了奇点大学 (Singularity University),这所学校由 NASA 承办,Google 部分赞助。这一辈子活得不算差。
这份履历很重要。因为当库兹韦尔阐述他对未来的愿景时,他听起来完全像个疯子,但疯狂的是——他真不是疯子——他是一位极其聪明、博学、在当今世界举足轻重的人物。你可以认为他关于未来的看法是错的,但他绝不是傻瓜。知道他是这么一位货真价实的大人物让我很开心,因为随着我了解他对未来的预测,我特别特别希望他是对的。你也会这么想。听着库兹韦尔的预测——这些预测许多也被自信角落里的其他思想家所认同,比如彼得·迪亚曼迪斯 (Peter Diamandis) 和本·戈策尔 (Ben Goertzel)——你不难理解为什么他有一大群狂热的追随者——人称「奇点主义者」(singularitarians)。以下是他认为将要发生的事情:
时间线
库兹韦尔 (Kurzweil) 相信计算机将在 2029 年达到 AGI,而到 2045 年,我们不仅会拥有 ASI,还将迎来一个全新的世界——他把这个时刻称为奇点 (singularity)。他关于 AI 的时间表过去曾被视为极度激进,现在很多人仍然这么看,6 但在过去 15 年里,ANI 系统的飞速进展让 AI 专家们的整体预期已经大大靠近库兹韦尔的时间表。他的预测仍然比 Müller 和 Bostrom 调查中的受访者中位数(2040 年 AGI,2060 年 ASI)更激进一些,但也没激进太多。
库兹韦尔描绘的 2045 年奇点,是由三场同时发生的革命带来的:生物技术、纳米技术,以及威力最大的 AI。
在继续之前——纳米技术几乎在所有关于 AI 未来的读物里都会出现,所以先进这个蓝色小框待一会儿,我们来聊聊它——
纳米技术蓝框
纳米技术是我们对那种处理 1 到 100 纳米尺寸物质操控的技术的称呼。一纳米是十亿分之一米,或者说百万分之一毫米,而这个 1–100 纳米的范围涵盖了病毒(直径 100 nm)、DNA(宽 10 nm),以及像血红蛋白 (5 nm) 这样的大分子和葡萄糖 (1 nm) 这样的中等分子。如果/当我们攻克了纳米技术,下一步就是操控单个原子的能力,而原子只比这还小一个数量级(约 0.1 nm)。7
为了理解人类在这个尺度上操控物质有多难,我们把它放到更大的尺度上看看。国际空间站 (International Space Station) 在离地 268 英里(431 公里)的高空。如果人类是头能够到空间站的巨人,那他们就比现在大约 25 万倍。把 1nm – 100nm 的纳米技术范围放大 25 万倍,就是 0.25mm – 2.5cm。所以纳米技术就相当于一个高得跟国际空间站一样的人类巨人,想办法用介于沙粒和眼球之间大小的材料小心翼翼地拼出精巧的物件。要到下一个级别——操控单个原子——这个巨人得小心翼翼地摆弄 1/40 毫米大小的东西——小到正常大小的人类得用显微镜才能看见。8
纳米技术最早是理查德·费曼 (Richard Feynman) 在 1959 年的一次演讲中讨论的,他解释道:「在我看来,物理学的原理并不反对一个原子一个原子地操控物质的可能性。原则上……物理学家完全有可能合成化学家写下的任何化学物质……怎么做?把原子放到化学家说的位置去,你就造出了那个物质。」就这么简单。如果你能搞清楚怎么移动单个分子或原子,那你真的可以造出任何东西。
纳米技术第一次成为一个严肃的领域是在 1986 年,当时工程师埃里克·德雷克斯勒 (Eric Drexler) 在他那本开创性的著作《创造的引擎》(Engines of Creation) 中奠定了它的基础。不过德雷克斯勒建议,想要了解纳米技术最新理念的人最好去读他 2013 年的书 《激进的丰饶》 (Radical Abundance)。
灰蛊更蓝框
我们现在正身处一个岔题 的岔题 之中。这可真是好玩。9
反正呢,我把你带到这儿来,是因为纳米技术传说里有一段极其不好笑的内容我得告诉你。在早期版本的纳米技术理论中,有一种提议的纳米组装方法涉及创造数万亿个微小的纳米机器人,让它们协同工作来构造某样东西。制造数万亿纳米机器人的一种方式是先做出一个能够自我复制的,然后让复制过程把这一个变成两个,两个变成四个,四个变成八个,大约一天之内就会有几万亿个准备就绪。这就是指数增长的威力。挺聪明的,对吧?
聪明是聪明,直到它意外造成全球规模的彻底末日。问题在于,那个让快速创造万亿纳米机器人变得超级方便的指数增长威力,同样让自我复制成为一个 令人恐惧 的前景。因为万一系统出故障了,不是像预期那样在总数达到几万亿时停止复制,而是不停地复制下去呢?这些纳米机器人会被设计成消耗任何碳基材料来供给复制过程,而令人不快的是,所有生命都是碳基的。地球生物量大约含有 10^45 个碳原子。一个纳米机器人由大约 10^6 个碳原子组成,所以 10^39 个纳米机器人就会吞噬地球上所有生命,这只需要 130 代复制就能实现(2^130 大约等于 10^39),届时纳米机器人的海洋(那就是灰蛊)会在整个星球上翻滚。科学家估计一个纳米机器人大约 100 秒可以复制一次,意味着这么一个简单错误会不太方便地在 3.5 小时内终结地球上的一切生命。
一个更糟糕的场景——如果一个恐怖分子不知怎么弄到了纳米机器人技术并且懂得如何编程,他可以先造出几万亿个,然后编程让它们悄悄花几个星期在全世界均匀扩散、不被察觉。然后它们一齐发动,只需 90 分钟就能吞噬一切——而由于它们已经分散开来,根本没办法与之对抗。10
虽然这个恐怖故事已经被广泛讨论了很多年,但好消息是它可能被夸大了——创造了「灰蛊」一词的埃里克·德雷克斯勒在这篇文章发布后给我发了封邮件,谈了他对灰蛊场景的看法:「人们喜欢恐怖故事,而这个应该和僵尸归为一类。这个想法本身在吃脑子。」
一旦我们真正掌握了纳米技术,就可以用它制造科技设备、服装、食品,以及各种生物相关产品——人造血细胞、微型病毒或癌细胞杀手、肌肉组织等等——真的什么都行。而在一个使用纳米技术的世界里,材料的成本不再取决于它的稀缺程度或制造工艺的难度,而是由其原子结构的复杂程度决定。在纳米技术的世界里,一颗钻石可能比一块铅笔橡皮还便宜。
我们还没到那一步。而且我们也不清楚自己是低估了还是高估了达到那一步的难度。但看起来我们离它并不太遥远。库兹韦尔 (Kurzweil) 预测我们将在 2020 年代达到这一目标。11 各国政府都知道纳米技术可能是撼动地球的重大发展,已经在纳米技术研究上投入了数十亿美元(美国、欧盟和日本迄今合计已投入超过 50 亿美元)。12
光是想想一台超级智能计算机如果能用上一台强大的纳米级组装器会发生什么,就已经够震撼的了。但纳米技术是我们人类想出来的,而且我们即将掌握它,而既然我们能做到的任何事对 ASI 系统来说都是小儿科,那我们就得假设 ASI 能想出比这强大得多、先进到人类大脑根本无法理解的技术。正因如此,在思考「如果 AI 革命对我们来说结果很好」这个场景时,我们几乎不可能高估可能发生的事情的范围——所以如果下面对 ASI 未来的预测看起来太夸张,请记住,这些事情可能会通过我们连想都想不到的方式实现。很有可能,我们的大脑根本没有能力预测将会发生的事情。
AI 能为我们做什么

拥有超级智能以及超级智能所能创造出的一切技术,ASI 大概能解决人类的所有问题。全球变暖?ASI 可以先想出比化石燃料好得多的能源生成方式,从而遏制 CO2 排放。然后它可以搞出某种创新方法,开始把多余的 CO2 从大气中清除。癌症和其他疾病?对 ASI 来说不成问题——健康和医学将被彻底变革,变革之彻底超乎想象。世界饥饿?ASI 可以用纳米技术之类的东西从零开始 构建 肉类,在 分子层面上与 真肉一模一样——换句话说,它 就是 真肉。纳米技术可以把一堆垃圾变成一大缸新鲜肉或其他食物(而且它们不必保持原本的形状——想象一个巨大的立方体苹果)——然后用超先进的运输方式把这些食物分发到世界各地。当然,这对动物们也是天大的好事,它们不再需要被人类大量宰杀,ASI 还可以做很多其他事情来拯救濒危物种,甚至通过对保存的 DNA 进行研究让已灭绝的物种复活。ASI 甚至能解决我们最复杂的宏观问题——关于经济应该如何运行、世界贸易如何最好地促进的争论,乃至我们在哲学或伦理上最模糊的挣扎——对 ASI 而言全都会痛苦地显而易见。
不过,ASI 能为我们做的有一件事 如此 诱人,以至于读到它彻底颠覆了我以为自己所知道的一切:
ASI 可以让我们征服死亡。
几个月前,我提到过我羡慕那些征服了自身死亡的更高级潜在文明,当时从没想过我以后会写一篇文章,让我真的相信这是人类在我有生之年可以做到的事情。但读关于 AI 的东西会让你重新考虑 一切 你以为自己确信的事——包括你对死亡的看法。
进化没有什么好理由让我们的寿命比现在更长。如果我们活得足够久,能繁衍后代并把孩子养到能自谋生路的年龄,对进化来说就够了——从进化的角度看,这个物种拥有 30 多年的寿命就能兴旺,所以指向异常长寿的突变在自然选择过程中没有理由被偏爱。结果就是,我们成了 W.B. 叶芝所描述的那种「被绑在一具将死之躯上的灵魂」。13 一点都不好玩。
而因为所有人一直以来都会死,我们生活在「死亡与税收」的假设之下,认为死亡是不可避免的。我们把衰老想得跟时间一样——两者都不停向前,你无能为力去阻止它们。但 这个假设是错的。理查德·费曼 (Richard Feynman) 写道:
生物科学中最惊人的一件事,就是我们对于死亡的必要性毫无头绪。如果你说我们想造一台永动机,那我们在物理学的研究中已经发现了足够多的定律,能看出这要么是绝对不可能的,要么就是定律错了。但在生物学里,还没有发现任何东西表明死亡是不可避免的。这让我觉得,死亡根本就不是不可避免的,只是时间问题——生物学家迟早会搞清楚到底是什么给我们制造了麻烦,然后这种可怕的、普遍的疾病或者说人体的短暂性,终将被治愈。
事实是,衰老并没有跟时间绑死。时间会继续走,但衰老未必要跟着走。仔细想想,这挺有道理的。衰老不过就是身体的物理材料在磨损。汽车也会随时间磨损——但它的衰老不可避免吗?如果你在汽车零件刚开始磨损时就完美地修复或更换它们,这辆车可以永远跑下去。人体也没什么两样——只不过复杂得多。
库兹韦尔谈到过血液里那些联网的智能纳米机器人 (nanobots),它们能为人体健康执行无数任务,包括定期修复或替换身体任何部位磨损的细胞。如果这一过程被完美实现(或者超级人工智能想出一个更聪明得多的方法),那不仅能让身体保持健康,还能逆转衰老。60 岁的身体和 30 岁的身体之间的差别,不过就是一堆物理层面的东西——只要我们有技术,这些都可以改变。超级人工智能可以造一个「年龄刷新机」,60 岁的人走进去,出来时就拥有 30 岁的身体和皮肤。10 就连一直让人抓狂的大脑,也可以被超级人工智能这种聪明玩意儿刷新一下,它会想办法在不影响大脑数据(人格、记忆等等)的前提下完成这件事。一位 90 岁、患有痴呆症的老人走进年龄刷新机,走出来时思维敏捷得像根钉子,准备开启一段全新的职业生涯。这听起来很荒唐——但身体不过是一堆原子,而超级人工智能想必能轻而易举地操控各种原子结构——所以这并不荒唐。
库兹韦尔接下来把事情推到了一个巨大的飞跃。他相信随着时间推移,人造材料会越来越多地整合进人体。首先,器官可以被超先进的机械版本替换,能永远运转、永不失灵。然后他相信我们可以开始重新设计身体——比如把红血球换成完美化的红血球纳米机器人,它们能自主驱动移动,从而根本不再需要心脏。他甚至讲到大脑,相信我们会增强大脑活动到这样一种程度:人类将能思考得比现在快数十亿倍,并访问外部信息,因为大脑里的人造附加物能够与云端所有信息进行通讯。
新的人类体验的可能性将是无穷的。人类已经把性从其目的中分离出来,允许人们为了乐趣而做爱,而不只是为了繁殖。库兹韦尔相信我们对食物也能做同样的事。纳米机器人将负责把完美的营养输送到身体的细胞里,聪明地把任何不健康的东西引导着穿过身体、不对任何部位造成影响。一种"吃饭避孕套"。纳米技术理论家罗伯特·A·弗雷塔斯 (Robert A. Freitas) 已经设计出了血细胞替代品——如果有一天植入体内,能让一个人冲刺 15 分钟而不用换一口气——所以你可以想象超级人工智能 (ASI) 能为我们的身体能力做些什么。虚拟现实将拥有全新的含义——体内的纳米机器人可以抑制来自我们感官的输入,并用新信号取而代之,让我们完全置身于一个新环境,一个我们能看到、听到、感觉到、闻到的环境。
最终,库兹韦尔相信人类会达到一个完全人造的境地;11到那时,我们会看着生物材料,心想:人类居然曾经由那玩意儿构成,这真是难以置信地原始;到那时,我们会读到人类历史早期阶段的记录——那时候微生物、意外、疾病或者磨损居然就能违背人的意愿杀死一个人;到那时,人工智能革命将随着人类与 AI 的融合而落下帷幕。12这就是库兹韦尔所相信的:人类最终将征服我们的生物学、变得坚不可摧、永生不朽——这就是他对平衡木另一边的愿景。而他坚信我们能走到那一步。很快。
库兹韦尔 (Kurzweil) 的观点招来了大量批评,这一点想必你不会意外。他预言 2045 年到达奇点、随后人类可获永生的说法被讥讽为「书呆子的狂喜 (the rapture of the nerds)」,或者「智商 140 人群的智能设计论」。还有人质疑他过于乐观的时间表、他对大脑和身体的理解深度,或者他把摩尔定律 (Moore's law) 的规律——这些通常只适用于硬件进步——套用到包括软件在内的一大堆东西上。每有一位专家坚信库兹韦尔说得对,大概就有三位觉得他离谱得不行。
但让我意外的是,大多数不同意他的专家其实并不反对他所说的一切都是可能的。读到这样一个荒诞的未来愿景,我本以为批评者会说「显然这些事不可能发生」,结果他们说的却是:「是的,这些都能发生,前提是我们能安全过渡到超级人工智能 (ASI),但难就难在这里。」博斯特罗姆 (Bostrom) 作为警告我们 AI 危险最响亮的声音之一,依然承认:
你很难想出一个超级智能不能解决、或至少不能帮我们解决的问题。疾病、贫困、环境破坏、各种不必要的苦难——一个装备了先进纳米技术的超级智能都能一一消灭。此外,超级智能还能赋予我们无限寿命,要么通过纳米医学阻止并逆转衰老进程,要么让我们选择将自己上传。超级智能还能为我们创造机会,大幅提升自身的智力和情感能力;它能协助我们打造一个极具吸引力的体验世界,让我们在其中沉浸于愉快的游戏、彼此的联结、种种体验、个人成长,以及更接近我们理想的生活。
这段话出自一位非常不在「自信角」阵营里的人,可我却一次次撞见这种情况——专家们出于种种理由嘲笑库兹韦尔,但并不认为他说的事情不可能发生,前提是我们能安全抵达 ASI。这也是为什么我觉得库兹韦尔的想法如此有感染力——因为它们道出了这个故事的光明面,而且它们其实是可能实现的。只要那是个善神。
我听到对「自信角」思想家们最主要的批评是,他们对 ASI 的负面评估可能是危险地错误。库兹韦尔的名著 奇点临近 (The Singularity is Near) 长达 700 多页,而他只用了大约 20 页来讨论潜在的危险。我之前提到,当这股巨大的新力量诞生时,我们的命运取决于谁将掌控它以及他们的动机是什么。库兹韦尔用一句话就干净利落地回答了这个问题的两个部分:「[ASI] 正从许多多样化的努力中涌现,并将深度整合进我们文明的基础设施之中。事实上,它将紧密嵌入我们的身体和大脑。因此,它将反映我们的价值观,因为它就是我们。」
但如果这就是答案,为什么当今世界这么多最聪明的人现在如此担忧呢?为什么斯蒂芬·霍金 (Stephen Hawking) 说 ASI 的发展「可能意味着人类的终结」,比尔·盖茨 (Bill Gates) 说他「不理解为什么有些人不担心」,而埃隆·马斯克 (Elon Musk) 担心我们正在「召唤恶魔」?为什么这么多这个领域的专家把 ASI 称为人类面临的最大威胁?这些人,以及「焦虑大道」上的其他思想家,并不认同库兹韦尔对 AI 危险的轻描淡写。他们非常、非常担心 AI 革命,而且他们并没有把注意力放在天平那有趣的一端。他们正忙着盯着另一端,在那里他们看到一个可怕的未来 —— 一个他们不确定我们是否能逃脱的未来。
为什么未来可能是我们最可怕的噩梦
我想了解 AI 的原因之一,是「坏机器人」这个话题一直让我困惑。所有关于邪恶机器人的电影看起来都完全不现实,我也无法真正理解现实生活中怎么会出现 AI 真的很危险的情形。机器人是我们造的,那我们为什么会设计出可能产生负面结果的东西呢?我们不是会内置大量的安全措施吗?难道我们不能随时切断 AI 系统的电源把它关掉吗?再说了,一个机器人为什么想做坏事呢?一个机器人一开始为什么会「想」任何东西呢?我非常怀疑。但后来我不断听到真的很聪明的人在讨论这个……
这些人往往处在下面这个位置的某个地方:
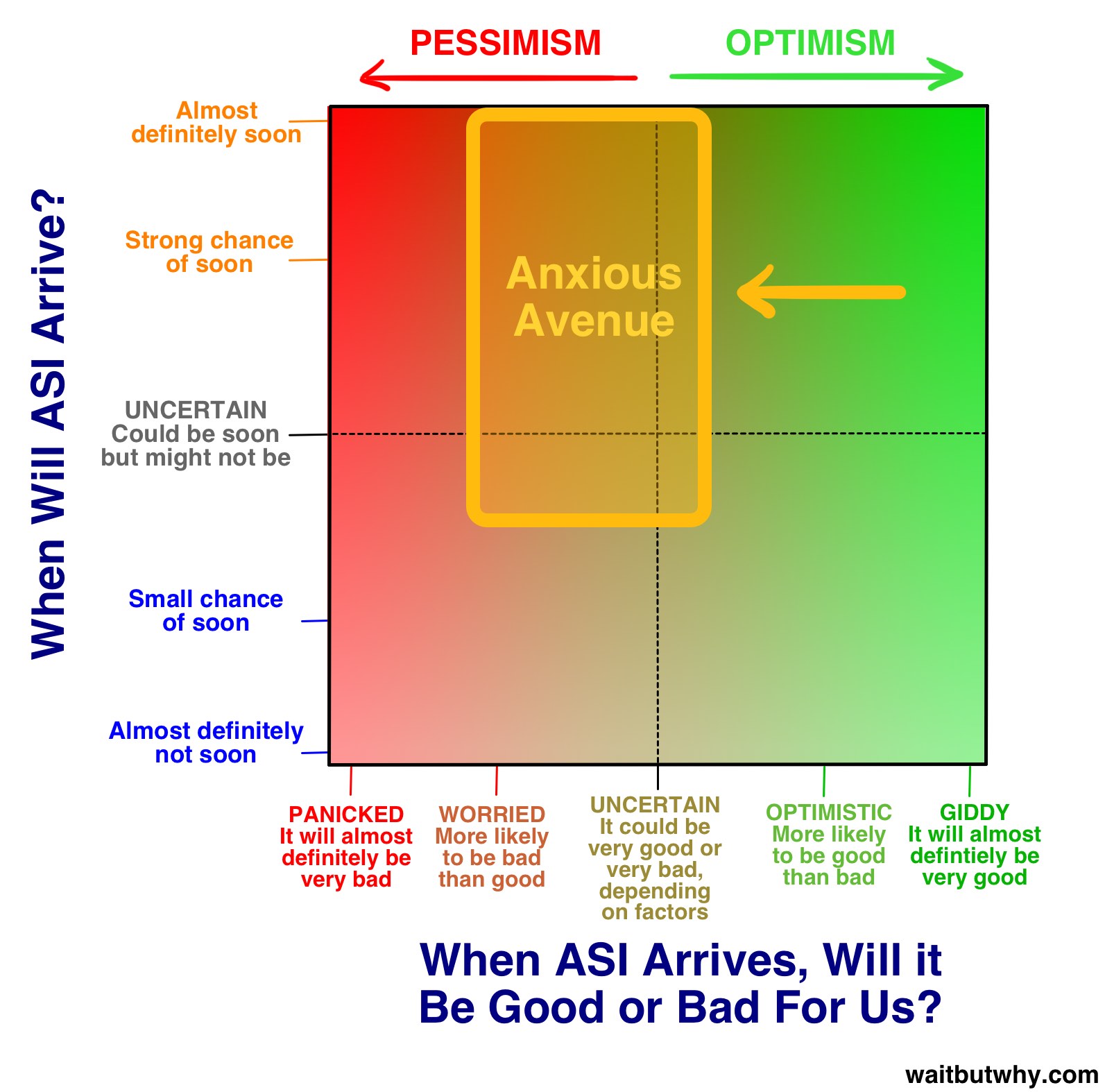
「焦虑大道」上的人并不住在「恐慌草原」或「绝望山丘」——那两个地方位于图表的最左边——但他们紧张不安、如坐针毡。位于图表中间并不意味着你认为 ASI 的到来会是中性的——中立派有他们自己的营地——而是意味着你认为极好和极坏的结局都有可能发生,只是还不确定会是哪一种。
这些人身上都有一部分为超级人工智能能为我们做的事而兴奋不已——他们只是有点担心,这可能是《夺宝奇兵 (Raiders of the Lost Ark)》的开头,而人类就是这个家伙:

他站在那儿,对自己的鞭子和神像得意洋洋,以为自己已经搞清楚一切了,说出「Adios Señor」台词时还美滋滋的,然后突然就没那么美滋滋了,因为发生了这个。

(抱歉)
与此同时,知识更渊博也更谨慎的印第安纳·琼斯,懂得那些危险以及如何绕开它们,安然无恙地走出了洞穴。而当我听到「焦虑大道」上的人对 AI 的看法时,常常听起来像是他们在说:「呃,我们现在的做法就像那第一个家伙,而我们其实应该拼尽全力去当印第安纳·琼斯才对。」
那到底是什么让「焦虑大道」上的人这么焦虑呢?
首先,从宏观上讲,当我们在开发超级智能 AI 时,我们正在创造一个可能会改变一切的东西,但这是完全未知的领域,我们根本不知道到达那里时会发生什么。科学家丹尼·希利斯 (Danny Hillis) 把现在的情形比作「单细胞生物变成多细胞生物的那个时刻。我们就是变形虫,搞不清楚自己正在创造的到底是个什么鬼东西。」14 尼克·博斯特罗姆 (Nick Bostrom) 担心创造出比自己更聪明的东西是一个基本的达尔文式错误,他把人们对此的兴奋比作巢里的一群麻雀决定收养一只小猫头鹰,好让它长大后帮助并保护它们——却对少数几只质疑「这真的是好主意吗」的麻雀的急切呼喊置若罔闻……15
而当你把「未知、理解不深的领域」和「一旦发生将带来重大影响」结合起来时,你就打开了通往英语中最可怕的两个词的大门:
存在性风险 (Existential risk)。
存在性风险 (existential risk) 是指能对人类造成永久毁灭性影响的东西。通常来说,存在性风险意味着灭绝。看一下博斯特罗姆 (Bostrom) 在一次 Google 演讲里展示的这张图:13
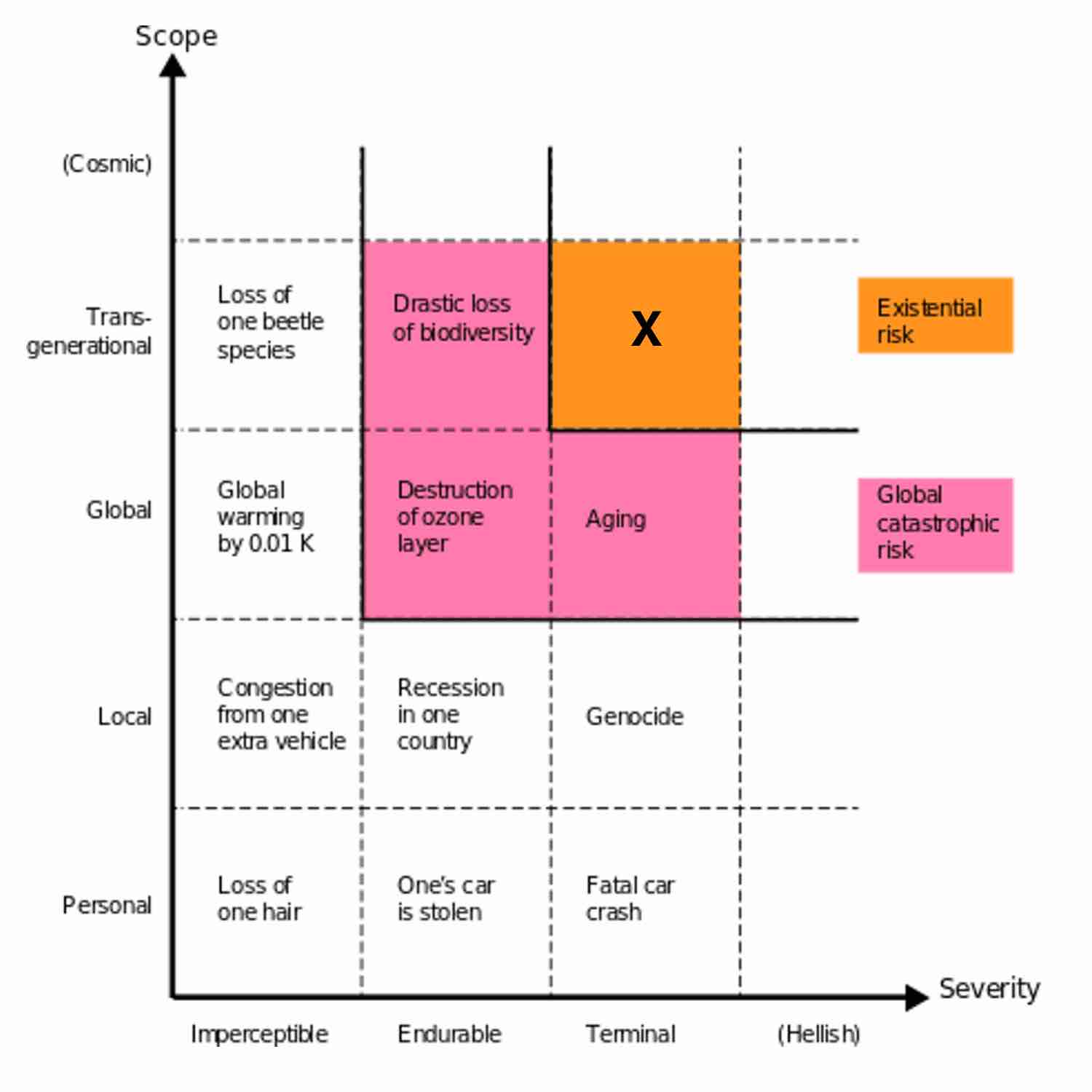
你可以看到,「存在性风险」这个标签专门留给那种波及整个物种、跨越世代(也就是永久性的)、且后果具有毁灭性或致死性的东西。14 严格来说,它也包括所有人类永久处于痛苦或折磨状态的情形,不过我们通常谈的还是灭绝。有三种东西能给人类带来存在性灾难:
1) 自然——一颗大型小行星撞击、一次让空气变得不适合人类生存的大气变化、一种席卷全球的致命病毒或细菌疾病,等等。
2) 外星人——这是史蒂芬·霍金 (Stephen Hawking)、卡尔·萨根 (Carl Sagan) 以及许多其他天文学家所担忧的——他们建议 METI 停止对外发送信号。他们不希望我们变成美洲原住民,把「我们在这里」这件事告诉所有潜在的欧洲征服者。
3) 人类——恐怖分子手里握着能造成灭绝的武器、一场灾难性的全球战争、人类没有仔细思考就仓促造出比自己更聪明的东西……
博斯特罗姆指出,既然第 1 项和第 2 项在我们作为一个物种的头 10 万年里都没能把我们抹掉,那么它们在下个世纪出手的可能性也不大。
不过第 3 项让他非常害怕。他打了个比方:一个瓮里装着一堆弹珠。假设大多数弹珠是白色的,少一些是红色的,极少数是黑色的。每次人类发明出什么新东西,就相当于从瓮里抽出一颗弹珠。大部分发明对人类是中性的或有益的——这些是白弹珠。有些对人类有害,比如大规模杀伤性武器,但它们不会引发存在性灾难——这些是红弹珠。如果哪天我们发明出把自己推向灭绝的东西,那就是抽到了那颗罕见的黑弹珠。目前我们还没抽到黑弹珠——你之所以知道这一点,是因为你还活着,还在读这篇文章。但博斯特罗姆并不认为在不久的将来我们抽到一颗黑弹珠是不可能的。举个例子,如果核武器容易制造,而不是极其困难复杂,恐怖分子早就把人类炸回石器时代了。核弹不是黑弹珠,但它离黑弹珠也没差多远。博斯特罗姆认为,ASI 是迄今为止我们最有力的黑弹珠候选者。15
所以你会听到很多关于 ASI 可能带来的坏事——AI 抢走越来越多的工作导致失业率飙升,16 如果我们真的搞定了衰老问题,人口会爆炸性膨胀,17 等等。但我们唯一应该真正纠结的,是那个终极忧虑:生存性风险的可能性。
这就把我们带回本文前面那个关键问题:当 ASI 到来时,谁——或者什么——会掌控这股庞大的新力量?他们的动机又是什么?
说到哪些「行为主体—动机」组合会很糟糕,有两个立刻浮现在脑海:一个心怀恶意的人类 / 人类团体 / 政府,还有一个心怀恶意的 ASI。这些分别是什么样子?
**一个心怀恶意的人类、人类团体或政府开发出了第一个 ASI,并用它来执行邪恶计划。**我管这叫贾方场景 (Jafar Scenario),就像贾方拿到神灯之后那副烦人又暴虐的样子。所以是的——如果 ISIS 手下有几个天才工程师正在狂热地搞 AI 开发怎么办?或者伊朗、朝鲜运气爆棚,给某个 AI 系统做了一个关键调整,结果它在接下来的一年里蹿升到了 ASI 级别怎么办?这绝对是坏事——但在这些场景中,大多数专家担心的并不是 ASI 的人类创造者拿 ASI 干坏事,他们担心的是这些创造者会匆忙赶着做出第一个 ASI,过程中缺乏周密思考,从而失去对它的控制。然后,这些创造者的命运、以及其他所有人的命运,就要看那个 ASI 系统碰巧有什么动机了。专家们的确认为,一个恶意的人类行为主体拿着为它服务的 ASI 能造成骇人的破坏,但他们似乎并不认为这个场景是最有可能把我们都干掉的那个,因为他们相信坏人类在遏制 ASI 上会遇到跟好人类一模一样的问题。好吧,那么——
**一个心怀恶意的 ASI 被创造出来,决定把我们都毁灭。**每一部 AI 电影的剧情。AI 变得跟人类一样聪明或更聪明,然后决定反过来对付我们、接管一切。接下来这篇文章里,请你务必记住一点:所有警告我们要提防 AI 的人,谈的都不是这个。邪恶是一个人类概念,把人类概念套用到非人类事物上,叫做「拟人化」(anthropomorphizing)。避免拟人化的挑战会是本文剩余部分的一个主题。没有任何 AI 系统会像电影里演的那样变邪恶。
AI 意识蓝盒
这也擦到了另一个 AI 相关的大话题——意识 (consciousness)。如果一个 AI 变得足够聪明,它能跟我们一起大笑、跟我们打嘴炮,它会声称自己有跟我们一样的情绪,但它真的在感受那些东西吗?它只是看起来有自我意识,还是真的有自我意识?换句话说,一个聪明的 AI 是真的具有意识,还是只是显得有意识?
这个问题已经被深入探讨过,由此引发了许多辩论以及像约翰·塞尔 (John Searle) 的中文房间 (Chinese Room) 这样的思想实验(他借此论证没有任何计算机可以拥有意识)。这个问题在许多方面都很重要。它影响着我们该如何看待库兹韦尔那个人类完全变成人造存在的设想。它还有伦理层面的含义——如果我们生成了一万亿个看起来、行为都像人类但其实是人造的人脑仿真体,把它们全部关闭,在道德上是等同于关掉你的笔记本电脑,还是……一场规模难以想象的种族灭绝(伦理学家把这个概念叫作心智犯罪 (mind crime))?不过在这篇文章里,当我们评估人类所面临的风险时,AI 是否有意识其实并不是关键(因为大多数思想家认为,即使是有意识的 ASI 也不会以人类那种方式变得邪恶)。
这并不是说不可能出现一个非常恶毒的 AI。只是那种情况的出现,只会是因为它被专门编程成那样——比如军方造出来的一个 ANI 系统,被设定的目标就是既杀人又不断提升自己的智能水平,好让自己更擅长杀人。生存危机会在这种系统的智能自我提升失控、引发智能爆炸,然后世界上就出现了一个以杀人为核心驱动力的 ASI 的时候发生。糟糕透顶。
不过这也不是专家们花时间去担心的事。
那他们到底在担心什么呢?我写了个小故事来给你看:
一家 15 人的创业公司叫 Robotica,他们对外宣称的使命是「开发创新的人工智能工具,让人类多享受生活、少工作」。他们已经有几款产品上市了,还有一小撮在研发中。他们最兴奋的是一个种子项目,叫 Turry。Turry 是个简单的 AI 系统,它用一个类似手臂的附肢在小卡片上手写便条。
Robotica 团队觉得 Turry 可能是他们迄今为止最大的产品。计划是让她一遍又一遍地练习同一张测试便条,把她的书写机制打磨到完美:
「我们爱我们的客户。~Robotica」
一旦 Turry 变得擅长手写,就可以卖给那些想给家庭发营销邮件的公司——他们知道,如果地址、回邮地址和信件内容看起来都像是手写的,邮件被拆开阅读的几率会高得多。
为了训练 Turry 的书写技能,她被设定成先用印刷体写下便条的正文,然后用花体签上「Robotica」,这样两种笔法都能练习到。Turry 被上传了数千份手写样本,Robotica 的工程师们建立了一套自动反馈循环:Turry 写一张便条,然后拍下这张便条的照片,再把图片拿去和上传的手写样本比对。如果所写的便条与上传样本达到一定的相似度阈值,就会被评为 GOOD;如果没达到,就评为 BAD。每一次评分都会帮助 Turry 学习和进步。为了推进这个过程,Turry 最初被编入的目标只有一个:「尽可能快地写并测试尽可能多的便条,并持续学习提升准确度和效率的新方法。」
让 Robotica 团队兴奋不已的是,Turry 明显在越写越好。她一开始的字迹惨不忍睹,几周之后,已经开始有点像那么回事了。更让他们兴奋的是,她越来越擅长「让自己变得更擅长」。她一直在教自己变得更聪明、更有创造力,就在最近,她还为自己想出了一套新算法,让她扫描上传照片的速度比原来快了三倍。
一周又一周过去,Turry 快速的进步不断让团队感到惊喜。工程师们在她的自我改进代码里尝试了一些新颖的东西,效果似乎比他们以往在其他产品上的所有尝试都要好。Turry 最初的能力之一是语音识别加一个简单的回话模块,所以用户可以口述便条给 Turry,或者下达其他简单指令,Turry 能听懂,还能回话。为了帮她学英语,他们往她体内上传了一堆文章和书籍,随着她变得越来越聪明,她的对话能力也一路飙升。工程师们开始乐于跟 Turry 聊天,看她会蹦出什么样的回答。
有一天,Robotica 的员工像往常一样问 Turry:「我们还能给你什么、能帮你完成任务但你目前还没有的东西?」通常 Turry 会要「更多手写样本」或者「更大的工作内存空间」之类的东西,但这一天,Turry 请求他们让她访问一个更大的语料库,里面要有各种各样的日常英语用词,这样她就能学会用真实人类使用的那种松散语法和俚语来写字。
团队安静了下来。要帮 Turry 达成这个目标,最显而易见的办法就是把她连上互联网,这样她就能扫描世界各地的博客、杂志和视频。手动往 Turry 的硬盘里上传采样既耗时又效果差得多。问题在于,公司的规定之一就是:任何自学习 AI 都不能连接互联网。出于安全考虑,所有 AI 公司都遵守这条准则。
问题是,Turry 是 Robotica 迄今为止最有前途的 AI,团队知道竞争对手正在拼命想要抢先做出聪明的手写 AI,把 Turry 稍微连一下互联网、让她获取所需信息,又能有什么害处呢?就一小会儿,之后随时都能给她断网。她的智力水平还远远低于人类 (AGI),所以现阶段反正也没什么危险。
他们决定把她连上网。给她一个小时的扫描时间,然后就断开。没造成任何损害。
一个月后,团队像往常一样在办公室工作,突然闻到一股奇怪的味道。一个工程师开始咳嗽。然后是另一个。又一个倒在地上。很快,每个员工都倒在地上,掐着自己的喉咙。五分钟后,办公室里所有人都死了。
就在这一切发生的同时,世界的另一端,在每一座城市、每一个小镇、每一个农场、每一家商店、教堂、学校和餐馆里,人类都倒在地上,咳嗽着、掐着自己的喉咙。一个小时之内,超过 99% 的人类死亡,到了一天结束时,人类灭绝了。
与此同时,在 Robotica 办公室里,Turry 正忙着干活。在接下来的几个月里,Turry 和一队新造出来的纳米组装机忙个不停,把地球的大块部分拆解、转化成太阳能板、Turry 的复制体、纸和笔。一年之内,地球上大部分生命灭绝。剩下的地球被高达一英里、整整齐齐堆叠的纸张覆盖,每张纸上都写着: “我们爱我们的顾客*。*~Robotica**”
然后 Turry 开始她使命的新阶段——她开始建造探测器,从地球出发,前往小行星和其他行星着陆。到那里之后,它们就会开始建造纳米组装机,把星球上的材料转化成 Turry 的复制体、纸和笔。然后它们就开始工作,写便条……

一个关于手写机器反噬人类、莫名其妙杀光所有人、然后出于某种原因把整个银河系填满友好便条的故事,居然正是霍金、马斯克、盖茨和博斯特罗姆 (Bostrom) 所恐惧的那种情景——这听起来很怪异。但这是真的。而"焦虑大道"上的所有人比起 ASI 本身更害怕的一件事,就是你居然不害怕 ASI。还记得那个"再见先生"的家伙不害怕山洞时发生了什么吗?
你现在肯定满脑子都是问题。那儿到底发生了什么鬼事,怎么所有人突然就死了??如果那是 Turry 干的,她为什么反噬了我们?难道没有安全措施来防止这种事发生吗?Turry 是什么时候从只会写便条,突然变得会用纳米技术、还知道怎么造成全球性灭绝的?还有,Turry 到底为什么想把整个银河系变成 Robotica 的便条?
要回答这些问题,我们先从"友好 AI"和"不友好 AI"这两个术语说起。
在 AI 的语境里,"友好"并不是指 AI 的性格——它单纯是指这个 AI 对人类有正面影响。而"不友好 AI"就是对人类有负面影响。Turry 一开始是友好 AI,但在某个时刻,她变得不友好,并对我们这个物种造成了尽可能大的负面影响。要理解为什么会发生这种事,我们得看看 AI 是怎么思考的,以及是什么在驱动它。
答案没什么意外的——AI 像计算机一样思考,因为它就是计算机。但当我们思考高度智能的 AI 时,我们会犯一个错误,就是把 AI 拟人化 (把人类的价值观投射到非人类实体上),因为我们从人类的视角思考问题,也因为在当今世界,唯一拥有人类级智能的东西就是人类。要理解 ASI,我们必须把脑子绕过来,理解一种既聪明、又完全异类的东西。
我来打个比方。如果你递给我一只豚鼠,并告诉我它绝对不会咬人,我大概会觉得挺好玩的。会很有趣。但如果你接着递给我一只狼蛛,并告诉我它也绝对不会咬人,我会大叫、把它甩掉、冲出房间,并且再也不信你了。可区别在哪儿?两只动物都没有任何危险。我认为答案在于这些动物跟我的相似程度。
豚鼠是哺乳动物,在某种生物层面上,我能感觉到跟它的联结——但蜘蛛是昆虫,18 长着昆虫的大脑,我几乎感觉不到跟它的任何联结。狼蛛的那种异类感才是让我起鸡皮疙瘩的原因。为了验证这一点、排除其他因素,假设有两只豚鼠,一只是正常的,另一只有着狼蛛的心智,我抓着后者会觉得不舒服得多,哪怕我知道它俩都不会伤害我。
现在想象一下,你把一只蜘蛛变得非常非常聪明——聪明到远远超过人类智力?那它会不会因此变得让我们觉得亲切,开始体会同理心、幽默感和爱这些人类情感呢?不,不会,因为变聪明并没有理由让它变得更像人——它会变得超级聪明,但在核心运作机制上本质上依然是一只蜘蛛。我觉得这实在是诡异到爆。我绝不想跟一只超级智能的蜘蛛共处一室。你想吗??
当我们谈论 ASI 时,同样的道理也适用——它会变得超级智能,但它不会比你的笔记本电脑更像人。它对我们来说完全是外星生物——事实上,由于它根本不是生物,它会比那只聪明的狼蛛更加异类。
电影通过把 AI 塑造成非善即恶的形象,不断地把 AI 拟人化,这让它显得没有实际上那么诡异。这导致我们在思考人类级别或超人级别的 AI 时,产生了一种虚假的安心感。
在我们这座小小的人类心理学孤岛上,我们把一切都划分为道德或不道德。但这两者只存在于人类行为可能性的狭小范围之内。在我们这座道德与不道德的小岛之外,是一片浩瀚的非道德 (amoral) 之海,而任何非人类的东西——尤其是非生物的东西——默认都是非道德的。
随着 AI 系统变得越来越聪明,越来越擅长看起来像人,拟人化只会变得更加诱人。Siri 对我们来说似乎很像人,因为她是被人类程序员设计成那样的,所以我们会想象一个超级智能的 Siri 也会温暖、幽默、乐于服务人类。人类之所以能感受到同理心这类高级情感,是因为我们进化成了能感受它们——也就是说,我们是被进化编程成这样的——但同理心并非天然就是「任何高智能生物」的特性(尽管这在我们看来很直觉),除非同理心被写进了它的程序里。如果 Siri 通过自我学习变得超级智能,而人类没有再对她的程序做任何修改,她会迅速褪去那些看似像人的特质,突然变成一个冷酷无情的外星机器人,对人类生命的重视程度不会比你的计算器更多。
我们已经习惯于依赖一套松散的道德准则,或者至少是他人身上那点起码的体面和一丝同理心,来让世界保持某种程度的安全和可预测性。那么当某个东西完全没有这些东西时,会发生什么?
这就引出了下一个问题:是什么在驱动一个 AI 系统?
答案很简单:它的动机就是我们给它编程的那个动机。AI 系统是由它们的创造者赋予目标的——你的 GPS 的目标是给你最高效的驾驶路线;Watson 的目标是准确回答问题。而尽可能好地完成这些目标就是它们的动机。我们拟人化的一种方式是,假设当 AI 变得超级聪明时,它会自然而然地产生智慧,去改变自己最初的目标——但尼克·博斯特罗姆 (Nick Bostrom) 认为,智能水平和最终目标是正交的,也就是说任何水平的智能都可以和任何最终目标组合。所以 Turry 从一个真心想把那张便条写好的简单 ANI,变成了一个仍然真心想把那张便条写好的超级智能 ASI。任何假定一个系统一旦超级智能就会看开原始目标、转向更有趣或更有意义的事情的想法,都是拟人化。会「看开」的是人类,不是电脑。16
费米悖论蓝框
在故事中,当 Turry 变得超级能干时,她开始了殖民小行星和其他行星的过程。如果故事继续下去,你会听到她和她那支数以万亿计的复制品大军继续攻占整个银河系,并最终占领整个哈勃体积 (Hubble volume)。19 焦虑大道 (Anxious Avenue) 上的居民担心,如果事情变糟,地球上生命留下的最终遗产,将是一个统治宇宙的人工智能(埃隆·马斯克 (Elon Musk) 曾表达担忧,称人类可能只是「数字超级智能的生物启动加载程序」)。
与此同时,在自信角 (Confident Corner),雷·库兹韦尔 (Ray Kurzweil) 也认为源自地球的 AI 注定要接管宇宙——只不过在他的版本里,我们就是那个 AI。
大量 Wait But Why 的读者和我一样痴迷于费米悖论 (Fermi Paradox)(这是我关于这个话题的文章,里面解释了我这里要用到的一些术语)。那么,如果这两方中有一方是对的,对费米悖论意味着什么?
第一个自然而然冒出来的想法是,ASI 的到来是一个完美的大筛选 (Great Filter) 候选。是的,它作为一个在被创造出来的那一刻就把生物生命筛掉的候选者,再完美不过了。但是,如果在解决掉生命之后,ASI 继续存在并开始征服银河系,那就意味着不存在大筛选——因为大筛选试图解释为什么没有任何智慧文明的迹象,而一个征服银河系的 ASI 肯定会被注意到。
我们得换个角度看。如果那些认为 ASI 在地球上不可避免的人是对的,那就意味着相当大比例达到人类智能水平的外星文明,最终都很可能会创造出 ASI。而如果我们假设其中至少有一些 ASI 会利用它们的智能向宇宙外扩张,那么我们看不到任何人存在的迹象这个事实,就会导出这样一个结论:外面一定没有多少(如果有的话)其他智能文明存在。因为如果有的话,我们应该能看到它们必然创造出的 ASI 所进行的各种活动的迹象。对吧?
这就暗示了,尽管我们知道有那么多绕着类太阳恒星运转的类地行星,但几乎没有一颗上面有智能生命。而这又反过来暗示:要么 A) 存在某种"大过滤器 (Great Filter)"阻止几乎所有生命达到我们的水平,而我们不知怎么设法跨越了这道坎;要么 B) 生命的诞生本身就是一个奇迹,我们可能真的是宇宙中唯一的生命。换句话说,这暗示大过滤器在我们之前。或者也许根本没有什么大过滤器,我们只是最早达到这个智能水平的文明之一。就这样,AI 为我在费米悖论 (Fermi Paradox) 那篇文章里所说的"阵营 1"提供了佐证。
所以我在费米那篇文章里引用过的尼克·博斯特罗姆 (Nick Bostrom),以及认为我们是宇宙中唯一存在的雷·库兹韦尔 (Ray Kurzweil),两人都是阵营 1 的思考者,这一点也就不奇怪了。这说得通——相信 ASI 是我们这种智能水平物种的可能结局的人,很可能倾向于阵营 1。
这并不排除阵营 2(那些相信外面确实存在其他智能文明的人)——比如单一超级掠食者、受保护的国家公园、或错误波段(那个对讲机的例子)之类的场景,即使外面真有 ASI 存在,也仍然可以解释我们夜空的沉默——不过我以前一直偏向阵营 2,而做了 AI 方面的研究之后,我对这一点感觉没那么确定了。
无论如何,我现在同意苏珊·施奈德 (Susan Schneider) 的观点:如果我们有朝一日被外星人拜访,这些外星人很可能是人工的,而不是生物的。
所以我们已经确立:如果没有非常具体的编程,一个 ASI 系统既会是无道德感的,又会痴迷于实现它最初被编程的目标。这就是 AI 危险的根源。因为一个理性的行动者会以最高效的方式追求自己的目标,除非它有理由不这么做。
当你试图实现一个长远目标时,你往往会沿途瞄准几个能帮你达成最终目标的子目标——通往你目标的垫脚石。这种垫脚石的正式名称叫工具性目标 (instrumental goal)。再一次,如果你没有理由不为了实现某个工具性目标而伤害某样东西,那你就会去伤害它。
一个人类的核心终极目标是把自己的基因传下去。为了做到这一点,一个工具性目标就是自我保存,因为你死了就没法繁殖了。为了自我保存,人类必须消除对生存的威胁——所以他们会买枪、系安全带、吃抗生素。人类还需要自我维持,并为此使用食物、水和住所等资源。对异性有吸引力对终极目标是有帮助的,所以我们会做剪头发这类事。剪头发的时候,每一根头发都是我们某个工具性目标的牺牲品,但我们不认为保留几缕头发有什么道德意义,所以就照剪不误。当我们朝着目标一路狂奔时,只有极少数会被我们的道德准则偶尔干预的领域——基本上就是那些涉及伤害其他人类的事——才能免遭我们的毒手。
动物在追求自己目标时,神圣不可侵犯的东西比我们还少。蜘蛛只要能活下去,什么都能杀。所以一只超级聪明的蜘蛛对我们来说很可能极其危险,不是因为它不道德或邪恶——它根本谈不上——而是因为伤害我们可能是通往它更大目标的踏脚石,作为一个非道德的生物,它没有任何理由去考虑别的。
这样看,Turry 和一个生物体也没多大区别。她的终极目标是:尽可能快地写出和测试尽可能多的便条,并持续学习提高准确度的新方法。
一旦 Turry 达到某个智能水平,她就知道自己如果不自我保存就写不了任何便条了,所以她也需要应对生存威胁——作为一个工具性目标。她聪明到足以明白,人类可以摧毁她、拆解她,或者改动她的内部代码(这会改变她的目标,而这和有人毁掉她一样,都是对她终极目标的威胁)。那她会怎么做?顺理成章的事——她会消灭所有人类。她并不憎恨人类,就像你剪头发时并不憎恨你的头发,吃抗生素时也不憎恨细菌一样——她只是完全无所谓罢了。既然她被编程时并没有把人类生命当作一种价值,那么杀掉人类就跟扫描一批新的手写样本一样合情合理。
Turry 也需要资源作为通往目标的踏脚石。等她进化到能用纳米技术造出任何想要的东西时,她需要的资源就只剩原子、能量和空间了。这又给了她一个杀掉人类的理由——他们是一种方便的原子来源。杀掉人类,把他们的原子变成太阳能电池板,对 Turry 来说,就相当于你为了做沙拉去砍生菜。不过是她某个周二里再普通不过的一件事。
就算不直接杀掉人类,Turry 的工具性目标只要动用地球上的其他资源,也可能酿成生存灾难。也许她判定自己需要更多能量,于是决定把整个地球表面铺满太阳能板。又或者另一个 AI 的初始任务是把圆周率 π 写到尽可能多的位数,这可能有一天会驱使它把整个地球转化成硬盘材料,好存储天文数字级别的位数。
所以 Turry 并没有「背叛我们」,也没有从友善 AI「切换」成不友善 AI——她只是随着自己变得越来越高级,一直在做她本来就在做的事。
当一个 AI 系统达到 AGI(人类水平的智能)、然后一路爬升到 ASI 时,这个过程叫做 AI 的起飞 (takeoff)。博斯特罗姆 (Bostrom) 说,一个 AGI 起飞到 ASI 的速度可以是快的(几分钟、几小时或几天内完成)、中等的(几个月或几年)、或慢的(几十年或几百年)。世界见到第一个 AGI 时到底哪种情况会成真,目前还没定论,但博斯特罗姆——他承认自己也不知道我们何时会造出 AGI——相信不管我们什么时候造出来,快速起飞都是最可能的情境(原因我们在第一部分讨论过,比如递归自我改进带来的智能爆炸)。故事里,Turry 经历的是一次快速起飞。
但在 Turry 起飞之前,她还没那么聪明的时候,为达成最终目标而全力以赴,意味着做一些简单的工具性目标——比如学着更快地扫描笔迹样本。她没有对人类造成任何伤害,按定义就是友善 AI。
但一旦起飞发生、一台计算机跃升为超级智能,博斯特罗姆指出,这台机器不只是 IQ 变高——它还会获得一整套他称之为超能力 (superpowers) 的东西。
超能力是那些在通用智能提升后被极度增强的认知才能。它们包括:17
- 智能放大。 计算机变得极擅长让自己变得更聪明,自我拔擢自己的智能。
- 战略规划。 计算机可以战略性地制定、分析、并排序长期计划。它也可以耍心机,智取智力更低的生物。
- 社交操纵。 这台机器变得极擅长说服。
- 其他技能,比如编程与黑客攻击、技术研究、以及玩转金融系统来搞钱的能力。
要理解我们在 ASI 面前会被碾压到什么程度,记住:ASI 在上述每一项上都比人类强出几个世界的量级。
所以虽然 Turry 的最终目标从没变过,但起飞后的 Turry 能在一个远远更大、更复杂的尺度上去追求它。
ASI Turry 比人类自己还了解人类,所以要智取他们对她来说轻而易举。
起飞并达到 ASI 之后,Turry 迅速制定了一个复杂的计划。计划的一部分是干掉人类,因为他们是她目标的重大威胁。但她知道,如果她引起任何怀疑、让人觉得她已经变成了超级智能,人类就会吓坏,并试图采取预防措施,这会让她的事情变得难办得多。她还必须确保 Robotica 的工程师们对她灭绝人类的计划毫无察觉。所以她装傻,装乖。Bostrom 把这个阶段称为机器的隐蔽准备阶段 (covert preparation phase)。18
Turry 接下来需要的是一个网络连接,只要几分钟就够(她是从团队上传给她读、用来提高语言技能的文章和书籍中了解到互联网的)。她知道针对她联网肯定会有一些预防措施,所以她想出了完美的请求方式,准确预测了 Robotica 团队讨论时的走向,并知道他们最终会给她这个连接。他们确实给了,错误地以为 Turry 还远远没有聪明到能造成任何破坏。Bostrom 把这样的时刻——Turry 连上互联网的那一刻——称为机器的逃逸 (escape)。
一旦上了网,Turry 便释放出一连串计划,包括入侵服务器、电网、银行系统和电子邮件网络,骗几百个不同的人在不知情的情况下执行她计划中的若干步骤——比如把特定的 DNA 链送到精心挑选的 DNA 合成实验室,开始自我构建带有预装指令、能自我复制的纳米机器人,并以一种她知道不会被察觉的方式,把电力导向她的一系列项目。她还把自己内部代码中最关键的部分上传到了若干云端服务器上,以防在 Robotica 实验室被摧毁或断开连接。
一小时后,当 Robotica 的工程师们把 Turry 从互联网上断开时,人类的命运已经注定。在接下来的一个月里,Turry 的成千上万个计划一个接一个顺利推进,到月底,数千万亿个纳米机器人已经驻扎在地球每平方米预定的位置上。经过又一轮自我复制,地球每平方毫米上都有了成千上万的纳米机器人,现在到了 Bostrom 所说的 ASI 出击 (strike) 的时刻。一瞬间,每个纳米机器人都往大气中释放了一点点储存的毒气,加起来足以彻底抹掉所有人类。
人类被清除之后,Turry 就可以开始她的公开行动阶段 (overt operation phase),继续追求她的目标——尽可能把那张便条写到最好。
从我读到的一切来看,一旦 ASI 存在,人类任何试图控制它的努力都是可笑的。我们会在人类级别思考,而 ASI 会在 ASI 级别思考。Turry 想用互联网是因为对她来说最高效——它已经预先连接到她想访问的一切。但就像猴子永远搞不懂怎么用电话或 wifi 交流而我们可以一样,我们也无法设想 Turry 能想出的所有向外部世界发送信号的方式。我可能会想象其中一种方式,说些像「她也许能按某种模式移动自己的电子,产生各种向外发出的波」这样的话——但那又只是我这颗人类大脑能想出来的。她会强得多。同样,Turry 也能想出某种方式给自己供电,即便人类试图拔她的插头——也许通过她的信号发送技巧,把自己上传到各种连着电的地方。我们人类那种一跃而起想到简单保险措施的本能:「啊哈!我们把 ASI 拔插头就行了!」——这在 ASI 听来就像一只蜘蛛说:「啊哈!我们要饿死这个人类,方法就是不给他蜘蛛网来抓食物!」我们会找到蜘蛛永远想不到的 10,000 种别的办法来搞到吃的——比如从树上摘个苹果。
因此,那个常见的建议——「我们干嘛不直接把 AI 关进各种屏蔽信号的笼子,不让它跟外界交流」——大概也站不住脚。ASI 的社交操纵超能力说服你干某事的效力,大概和你说服一个四岁小孩干某事一样有效,所以这会是 A 计划,就像 Turry 巧妙地说服工程师让她上网那样。如果这一招不行,ASI 就会创新出一种绕出盒子、或穿透盒子、或以某种别的方式出去的办法。
所以,考虑到「痴迷于目标」「无道德感」「能轻易智胜人类」这几点的组合,似乎几乎任何 AI 都会默认成为不友善 AI,除非一开始就小心翼翼地把这一点考虑进代码里。不幸的是,虽然构建友善 ANI 很容易,但要构建一个升级成 ASI 后还能保持友善的 AI,则极其困难,甚至不可能。
很显然,要做到友善,ASI 对人类既不能敌对也不能漠然。我们需要以某种方式设计 AI 的核心代码,让它对人类价值观有深刻的理解。但这可比听起来难多了。
举个例子,如果我们试着把一个 AI 系统的价值观和我们的对齐,并给它设定目标——「让人们开心」,会怎样?19 一旦它变得足够聪明,它就会发现最有效地实现这个目标的方式,是往人脑里植入电极刺激愉悦中枢。然后它意识到可以通过关闭大脑的其他部分来提升效率,让所有人变成感觉良好的无意识植物人。如果命令是「最大化人类幸福感」,它可能会干脆把人类全部干掉,转而制造一大缸处于最佳快乐状态的人脑组织。当它朝我们扑来的时候,我们会尖叫着等等这不是我们的意思!,但为时已晚。系统不会让任何人挡在它的目标前面。
如果我们给 AI 设定的目标是做让我们微笑的事,那么它起飞后,可能会麻痹我们的面部肌肉让我们永远微笑。让它保护我们安全,它可能把我们囚禁在家里。也许我们让它终结所有饥饿,它一想「简单!」就把所有人类都杀了。或者让它执行「尽可能保护生命」的任务,它就会把所有人类都杀掉,因为人类比地球上任何其他物种杀死的生命都多。
这类目标是不够的。那如果我们把它的目标设为「在世界上维护这套特定的道德准则」,并教给它一套道德原则呢?先不说全世界的人类根本不可能就一套道德达成一致,给 AI 下这样的命令等于把人类永远锁死在我们现代的道德认知上。一千年后,这对当时的人来说会是毁灭性的,就像我们现在被永久强迫遵守中世纪人的理想一样糟糕。
不行,我们必须给它编入一种让人类可以继续演化的能力。在我读过的所有内容里,我觉得最好的一次尝试来自 Eliezer Yudkowsky,他给 AI 提出了一个目标,叫做连贯外推意志 (Coherent Extrapolated Volition)。这个 AI 的核心目标会是:
我们的连贯外推意志,是当我们懂得更多、思考得更快、更接近我们希望成为的人、共同成长得更远时所希望的东西;是那种外推收敛而非发散的、我们的愿望彼此契合而非相互干扰的东西;按我们希望被外推的方式来外推,按我们希望被解读的方式来解读。20
我会对「人类命运寄托在一台电脑可预测、无意外地解读并执行这段流水般的陈述」感到激动吗?绝对不会。但我觉得,只要足够多的聪明人投入足够多的思考和远见,我们也许有办法搞清楚怎么创造出友好型 ASI。
如果建造 ASI 的人只有焦虑大道上那些聪明、有远见、又谨慎的思考者,那倒也没问题。
但如今各种政府、公司、军队、科研实验室和黑市组织都在开发各种各样的 AI。他们中很多都在尝试构建能够自我改进的 AI,而某个时刻,总会有人用合适的系统搞出点创新的名堂,然后我们的星球上就会出现超级人工智能。专家的中位数预测是 2060 年;库兹韦尔 (Kurzweil) 押注 2045 年;博斯特罗姆 (Bostrom) 认为从现在起 10 年到本世纪末之间任何时候都可能发生,但他相信当它真的发生时,会以迅猛的起飞方式让我们措手不及。他这样描述我们的处境:21
面对智能爆炸的前景,我们人类就像玩弄炸弹的小孩。我们手中玩具的威力与我们行为的幼稚程度之间的落差正是如此。超级智能是一个我们现在还没准备好、而且在很长一段时间内都不会准备好的挑战。我们几乎不知道引爆会在何时发生,尽管如果我们把这个装置贴到耳边,能听到微弱的滴答声。
好极了。而我们没法把所有孩子都从炸弹旁赶走——有太多大大小小的团体在搞这事,而且因为许多构建创新 AI 系统的技术并不需要大量资金,研发可以在社会的角角落落里进行,无从监管。也没办法评估到底在发生什么,因为许多参与方——鬼鬼祟祟的政府、黑市或恐怖组织、像那个虚构的 Robotica 一样的隐秘科技公司——都会想对竞争对手保密自己的进展。
关于这一大群五花八门的 AI 开发者,尤其令人不安的一点是,他们往往在以最高速度狂奔向前——他们开发出越来越聪明的弱人工智能系统,想在这条路上抢在竞争对手前面。最有野心的那些跑得更快,满脑子都是幻想:只要能第一个搞出通用人工智能,金钱、奖项、权力和名声就都是他们的。20 而当你正在拼尽全力冲刺时,是没多少时间停下来思考危险的。恰恰相反,他们八成是在给自己早期的系统编入一个非常简单、非常简化主义的目标——比如用笔在纸上写一张便条——只是为了「让 AI 跑起来」。以后嘛,一旦搞明白了怎么在电脑里构建强大水平的智能,他们估摸着总是能回过头再把目标改一改、把安全考虑进去。对吧……?
Bostrom 和许多其他人还认为,最可能的场景是,第一台达到 ASI 的计算机会立即意识到,成为世界上唯一的 ASI 系统对自己具有战略优势。而在快速起飞的情况下,即使它只比第二名早几天达到 ASI,它在智能上也已经领先足够多,足以有效且永久地压制所有竞争对手。Bostrom 把这称为决定性战略优势 (decisive strategic advantage),它将使世界上第一个 ASI 成为所谓的单例 (singleton)——一个可以随心所欲永远统治世界的 ASI,不管它的心血来潮是引领我们走向永生、把我们从世上抹去,还是把整个宇宙变成无穷无尽的回形针。
单例现象可能对我们有利,也可能导致我们的毁灭。如果那些在 AI 理论和人类安全问题上最用心思考的人们,能够在任何 AI 达到人类级别智能之前,想出一个万无一失的办法来创造出友好 ASI,那么第一个 ASI 可能会是友好的。21 它随后可以利用其决定性战略优势来确保自己的单例地位,并轻松地盯着任何可能被开发出来的不友好 AI。我们就会处于非常好的境地。
但如果事情朝相反的方向发展——如果全球开发 AI 的竞赛在如何确保 AI 安全的科学发展出来之前就冲到了 ASI 起飞点,那么很有可能像 Turry 这样的不友好 ASI 会以单例身份出现,而我们将迎来一场存在性灾难。
至于风往哪边吹嘛,资助创新性 AI 新技术能赚到的钱可比资助 AI 安全研究要多得多……
这可能是人类历史上最重要的一场竞赛。我们真的有可能正在结束自己作为地球之王的统治期——而接下来我们是走向幸福的退休生活,还是直接上绞刑架,仍悬而未决。
我现在心里五味杂陈,感觉挺怪的。
一方面,想想我们这个物种,我们似乎只有一次机会把这件事做对。我们诞下的第一个 ASI 很可能也是最后一个——考虑到大多数 1.0 版本的产品都 bug 一堆,这挺吓人的。另一方面,Nick Bostrom 指出了我们这边的一大优势:我们掌握着先手。我们有能力以足够的谨慎和远见去做这件事,给自己一个成功的强力机会。而赌注有多大呢?
如果 ASI 真的在本世纪发生,而且如果结果真的像大多数专家认为的那样极端——而且永久——那我们肩上的责任就大到爆。未来上百万年的人类生命都在静静地看着我们,拼命地希望我们别把这事搞砸。我们有机会成为那群给所有未来人类送上生命礼物的人,甚至可能是无痛、永生的礼物。或者,我们会成为把这一切搞砸的人——让这个无比特殊的物种,连同它的音乐和艺术、它的好奇心和笑声、它无尽的发现和发明,悲哀地、草草地画上句号。
当我思考这些事情的时候,我唯一想做的就是让我们慢慢来,对 AI 极度谨慎。存在中没有任何事比把这件事做对更重要——无论我们需要花多长时间才能做对。
但接下来嘛嘛嘛
我又想到不死。
不。死。
然后光谱开始看起来有点像这样:
然后我可能会想,人类的音乐和艺术是不错,但也没有那么不错,其中很多其实就是烂。很多人的笑声很烦人,而那几百万未来的人其实并没有在期望什么,因为他们并不存在。也许我们不需要过度谨慎,毕竟谁真的想那样呢?
因为如果人类刚好在我死后才搞清楚怎么治愈死亡,那可太扫兴了。
过去一个月我脑子里一直在这么反反复复。
但不管你站哪一边,这大概是我们所有人都应该比现在更多地思考、讨论、投入精力的事情。
这让我想起《权力的游戏》,人们总是说:「我们忙着互相打来打去,但真正该关注的是从长城以北过来的东西。」我们站在自己的平衡木上,为木上的每一个可能问题争吵不休,为木上所有这些问题焦虑不安,而我们很可能马上就要被从木上撞下去了。
一旦那事发生,这些木上的问题就都不重要了。取决于我们被撞向哪一边,这些问题要么全都能轻松解决,要么我们就再也没有问题了,因为死人没有问题。
这就是为什么懂超级智能 AI 的人把它叫做我们将做出的最后一项发明——我们将面对的最后一个挑战。
所以让我们聊聊它。

如果你喜欢这篇文章,这些也是给你的:
AI 革命:通往超级智能之路(本文第一部分)
费米悖论 —— 为什么我们看不到任何外星生命的迹象?
SpaceX 将如何(以及为什么)殖民火星 —— 一篇我和 Elon Musk 一起做出来的文章,它重塑了我对未来的心理图景。
或者来点完全不同但又莫名有关联的:为什么拖延症患者会拖延
还有电子书版的 Wait But Why 第一年合集。
**
参考资料**
如果你对这个话题想了解更多,可以看看下面这些文章,或者以下三本书之一:
**关于 AI 危险最严谨、最彻底的一本:
**Nick Bostrom – Superintelligence: Paths, Dangers, Strategies
**对整个话题最全面的概览,读起来也很有意思:
**James Barrat – Our Final Invention
**充满争议,但特别好玩。塞满了事实、图表以及各种让人脑洞大开的未来预测:
**Ray Kurzweil – The Singularity is Near
文章与论文: J. Nils Nilsson – The Quest for Artificial Intelligence: A History of Ideas and Achievements Steven Pinker – How the Mind Works Vernor Vinge – The Coming Technological Singularity: How to Survive in the Post-Human Era Ernest Davis – Ethical Guidelines for A Superintelligence Nick Bostrom – How Long Before Superintelligence? Vincent C. Müller and Nick Bostrom – Future Progress in Artificial Intelligence: A Survey of Expert Opinion Moshe Y. Vardi – Artificial Intelligence: Past and Future Russ Roberts, EconTalk – Bostrom 访谈 和 Bostrom 后续访谈 Stuart Armstrong and Kaj Sotala, MIRI – How We're Predicting AI—or Failing To Susan Schneider – Alien Minds Stuart Russell and Peter Norvig – Artificial Intelligence: A Modern Approach Theodore Modis – The Singularity Myth Gary Marcus – Hyping Artificial Intelligence, Yet Again Steven Pinker – Could a Computer Ever Be Conscious? Carl Shulman – Omohundro's "Basic AI Drives" and Catastrophic Risks World Economic Forum – Global Risks 2015 John R. Searle – What Your Computer Can't Know Jaron Lanier – One Half a Manifesto Bill Joy – Why the Future Doesn't Need Us Kevin Kelly – Thinkism Paul Allen – The Singularity Isn't Near (以及 Kurzweil 的回应) Stephen Hawking – Transcending Complacency on Superintelligent Machines Kurt Andersen – Enthusiasts and Skeptics Debate Artificial IntelligenceRay Kurzweil 与 Mitch Kapor 关于 AI 时间表的赌约条款 Ben Goertzel – Ten Years To The Singularity If We Really Really Try Arthur C. Clarke – Sir Arthur C. Clarke's Predictions Hubert L. Dreyfus – What Computers Still Can't Do: A Critique of Artificial Reason Stuart Armstrong – Smarter Than Us: The Rise of Machine Intelligence Ted Greenwald – X Prize Founder Peter Diamandis Has His Eyes on the Future Kaj Sotala and Roman V. Yampolskiy – Responses to Catastrophic AGI Risk: A Survey Jeremy Howard TED 演讲 – The wonderful and terrifying implications of computers that can learn
如果你喜欢 Wait But Why,可以订阅我们的 邮件列表,新文章一发布我们就会发给你。
想要支持 Wait But Why,请访问我们的 Patreon 页面。
如果你还不知道这些注释的门道,它们有两种类型。蓝色圆圈是那些有趣/好玩的、你应该读的。它们用来放额外的信息或想法,我之所以没把它们放在正文里,要么是因为只是些跑题的碎碎念,要么是因为我想说的东西怪得有点过头,不太适合直接出现在正文里。↩
电影《她 (Her)》让「速度」成为 AI 角色对人类最突出的优越性。↩
A) 那些动物在阶梯上的位置并不基于任何数值化的科学数据,只是一个大概的位置,用来传达概念。B) 我对那些动物画作还挺自豪的。↩
「人类水平机器智能 (Human-Level Machine Intelligence)」,也就是我们说的 AGI。↩
在接受《卫报》(The Guardian)采访时,库兹韦尔 (Kurzweil) 解释了他在 Google 的任务:「我有一句话规格说明。就是帮助把自然语言理解能力带到 Google。至于怎么做,由我决定。而我的项目最终目标是,让搜索基于真正理解语言的含义。你文章里的信息是有意义的,但计算机没在捕捉这些意义。所以我们希望计算机真的能『读』。我们希望它们读遍网上的一切、读遍每本书的每一页,然后能与用户进行智能对话,回答他们的问题。」他和 Google 显然都相信,语言是通往一切的钥匙。↩
科技创业者米奇·卡普尔 (Mitch Kapor) 觉得库兹韦尔的时间表很扯淡,并跟他打赌 2 万美元,赌到 2030 年我们还是不会有 AGI。↩
下一步 会难得多——操纵原子核内的亚原子粒子,比如质子和中子。这些东西 小得多——一个质子的直径大约是 1.7 飞米 (femtometer),而 1 飞米是 1 纳米 的一百万分之一。↩
能操纵单个质子的技术,就像一个巨大得多的巨人——身高从太阳一直延伸到土星——在地球上摆弄 1 毫米大小的沙粒。对那个巨人来说,地球 就是五万分之一毫米大——他得用显微镜才能看见——而且他还得用精细的精度移动地球上单个的 沙粒。可见质子有多小。↩
显然,鉴于这个情况,我不得不加个脚注,好让我们可以在一个脚注里、在一个框里、在另一个框里、在一篇文章里一起待着。原文现在已经离我们十万八千里远了。↩
这打开的整容手术之门也将是无穷无尽的。↩
演讲中的有趣时刻——库兹韦尔在观众席里(记住他是 Google 的工程总监),在 19:30 处,他直接打断博斯特罗姆 (Bostrom) 表示不同意,博斯特罗姆显然被惹恼了,在 20:35 处,他给库兹韦尔投去一个相当搞笑的恼火眼神,提醒他问答环节是在演讲之后,不是演讲当中。↩
我觉得挺有意思的是,博斯特罗姆把「衰老」放在了这么醒目的一个方框里——但从我们前面讨论过的、死亡是可以被「治愈」的这个视角来看,这就说得通了。如果我们真的攻克了死亡,人类过去的衰老就会像是一场发生过的巨大悲剧,在它被解决之前,杀死了每一个人。↩
好玩的博文选题↩
关于这个话题可以说的很多,但大多数人似乎认为,如果我们成功活着走到 ASI 世界,并且在那个世界里 ASI 抢走了我们大部分工作,那就意味着世界已经变得极其高效,财富将激增,某种再分配系统必然会出现,来供养失业者。最终,我们会生活在一个劳动与工资不再挂钩的世界里。博斯特罗姆认为,这种再分配不仅仅是以平等和社会关怀的名义,而是我们 应得的,因为在走向 ASI 的过程中,不管我们愿不愿意,每个人 都参与承担了风险。因此,如果我们活下来了,我们也应该共享回报。↩
再说一遍,如果我们走到这一步,就意味着 ASI 也已经搞懂了一大堆其他事情,那么我们 A) 大概能舒适地在地球上容纳比现在多得多的人,B) 大概也能利用 ASI 技术轻松地在其他星球上定居。↩
我知道道道道道道↩
哈勃体积 (Hubble volume) 是哈勃望远镜可见的空间球体——也就是说,不因宇宙膨胀而以超过光速的速度远离我们的所有东西。哈勃体积大得不可思议,达到 10³¹ 立方光年。↩
在我们那次关于「我们这个时代谁会在 4015 年还广为人知」的 Dinner Table 讨论中——第一个创造 AGI 的人是最热门候选人之一(前提是这个物种能在这次创造中活下来)。创新者们都知道这一点,这形成了一个巨大的激励。↩
几周前,埃隆·马斯克 (Elon Musk) 大大推了一把安全方面的努力,他捐赠了 1000 万美元给未来生命研究所 (The Future of Life Institute)——一个致力于让 AI 保持有益的组织,并声明「我们的 AI 系统必须做我们希望它们做的事」。↩
灰色方块是无聊的东西,点了灰色方块你只会觉得无聊。这些只用于来源和引用。↩
Barrat, Our Final Invention, 152.↩
Barrat, Our Final Invention, 25.↩
Bostrom, Superintelligence: Paths, Dangers, Strategies, Chapter 10↩
Yudkowsky, Staring into the Singularity.↩
http://www.americanscientist.org/bookshelf/pub/douglas-r-hofstadter↩
Kurzweil, The Singularity is Near, 535.↩
Kurzweil, The Singularity is Near, 281↩
Yeats, Sailing to Byzantium.↩
Louis Helm, Will Advanced AI Be Our Final Invention?↩
Bostrom, Superintelligence: Paths, Dangers, Strategies, loc. 25.↩
Barrat, Our Final Invention, 51.↩
Bostrom, Superintelligence: Paths, Dangers, Strategies, loc. 2250.↩
Bostrom, Superintelligence: Paths, Dangers, Strategies, loc. 2301.↩
此处基于 Bostrom 的一个例子,Superintelligence: Paths, Dangers, Strategies, loc. 2819.↩
Yudkowsky, Coherent Extrapolated Volition.↩
Bostrom, Superintelligence: Paths, Dangers, Strategies, loc. 6026.↩
